

У 2013 році інженери Google підрахували: якщо запустити розпізнавання мови для всіх користувачів лише на три хвилини на день, знадобиться подвоїти кількість дата-центрів компанії. На той момент звичайні CPU та GPU вже не могли впоратися з експоненційним зростанням обчислювальних потреб нейронних мереж.
Саме тоді виникла ідея створити повністю новий тип процесора — TPU (Tensor Processing Unit). Цей тензорний чіп, розроблений в рекордні терміни, не тільки розв'язав проблему Google, а й суттєво вплинув на індустрію штучного інтелекту.
«Ми зробили приблизні розрахунки й зрозуміли, що ми маємо подвоїти кількість серверів у дата-центрах. Але винайшли кращий спосіб», — розповідає Джефф Дін, головний науковий співробітник Google.
Особливості архітектури
В той час як центральні процесори (CPU) проєктувалися як «універсальні мізки», а графічні (GPU) дозволяли значно ефективніше працювати з графікою та відео, тензорні процесори були розроблені спеціально для штучного інтелекту, а саме для обчислень, що необхідні для побудови та запуску моделей ШІ.
Google розробила хмарні TPU як матричні процесори — вони не можуть запустити текстові редактори або фінансові застосунки, зате здатні швидко обробляти матриці, багаторазово повторюючи операції множення і накопичення. Процесор містить тисячі таких помножувачів-накопичувачів, які формують велику фізичну матрицю — саме вона утворює систолічну матричну архітектуру.
Наприклад, в процесорі TPU v3 одразу дві матриці по 128 x 128 ALU (арифметико-логічних пристроїв) на одному процесорі. TPU завантажує дані з черги вхідного потоку та зберігає їх у пам'яті, а після завершення обчислень перенаправляє результати у чергу вихідного потоку. Потім хост зчитує результати з черги вихідного потоку та зберігає їх у пам'яті.
Історія появи TPU-процесорів
Лише один рік і три місяці знадобилося Google, щоб розробити, верифікувати та розгорнути у своїх дата-центрах перший TPU-чіп. Спочатку компанія планувала партію на менше ніж 10 тисяч чіпів TPU v1, але в результаті їх було вироблено понад 100 тисяч — все через великий внутрішній попит.
Цей процесор ідеально підходив для різноманітних застосунків в екосистемі техногіганта: від пошукових сервісів до AlphaGo — розробленої Google DeepMind програми для гри в го.
Перший TPU (v1) був впроваджений ще у 2015 році — тоді, коли ринок штучного інтелекту почав переходити від досліджень до перших сміливих експериментів у різних галузях, а великі компанії почали конкурувати у цій площині та боротися за лідерство у глибокому навчанні та власних ML-платформах.
Процесор продемонстрував збільшення продуктивності у 15-30 разів та у 30-80 разів краще співвідношення продуктивність-на-ват порівняно з сучасними CPU та GPU. Перша версія TPU містила 65,536 8-бітних цілочисельних множників і могла виконувати 92 тераоперації на секунду.
Ці переваги допомогли підтримувати роботу багатьох сервісів, зокрема реклами, пошуку, розпізнавання голосу, софту для безпілотних авто, а також запускати нейромережі в масштабі та за доступною ціною.
Через 10 років, у 2025-му був анонсований тензорний процесор шостого покоління — TPU Trillium, можливості якого значно перевершують той самий перший TPU-чіп. Лише у порівнянні з попередником, TPU v5e, він забезпечує приріст обчислювальної потужності у 4,7 раза!
Еволюцію тензорних процесорів можна спостерігати в таблиці:
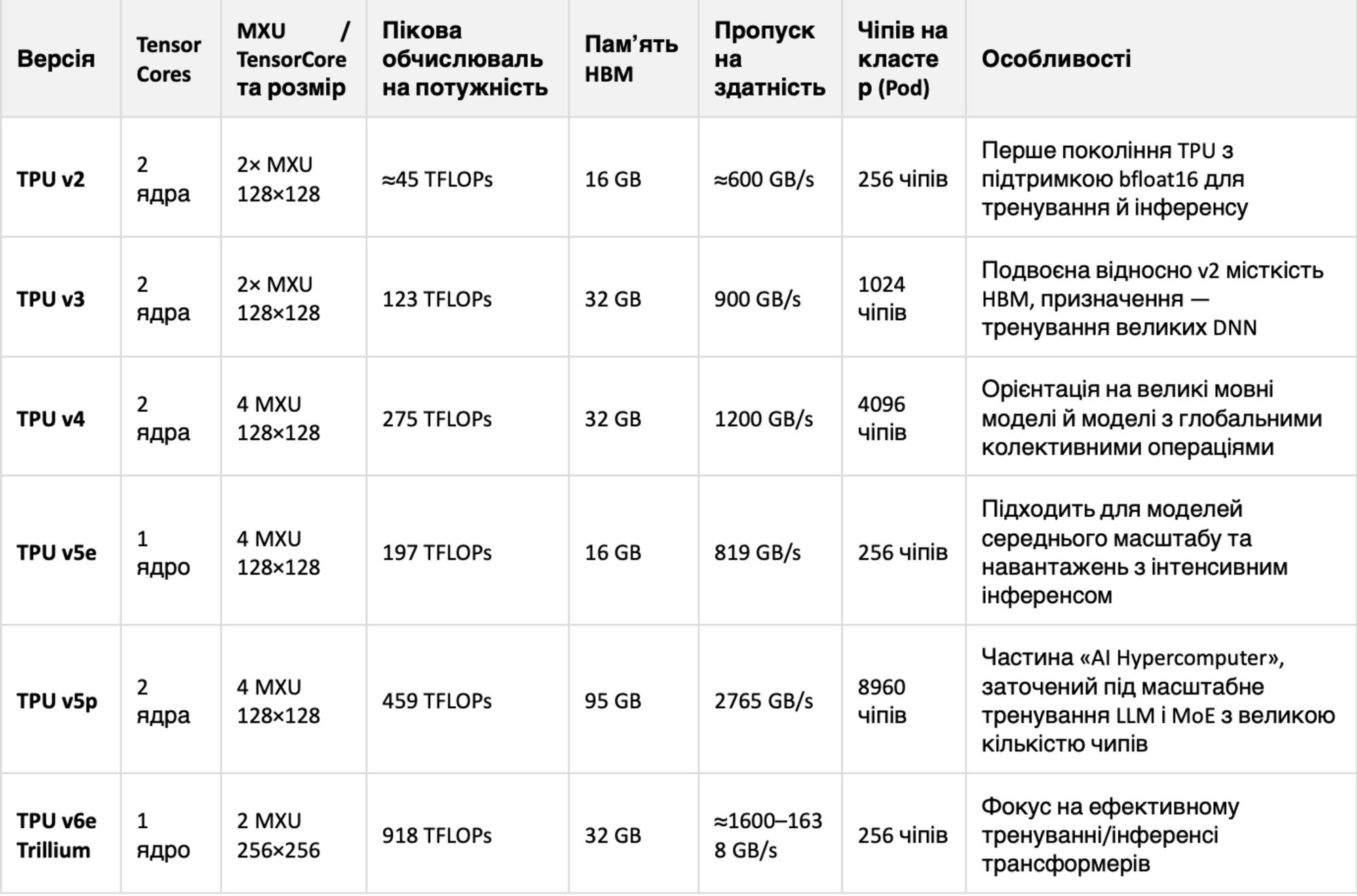
Найближчим часом має з’явитися TPU сьомого покоління з кодовою назвою Ironwood. В Google розповіли, що цей тензорний процесор матиме два ядра та 4 MXU 256×256, а його пікова обчислювальна потужність становитиме 2307 TFLOPs. Модель буде орієнтована на великомасштабне тренування та інференс.
Так, один Pod з 9216 чипів дає змогу тренувати та розгортати моделі масштабів, які раніше вимагали розподілення навантаження між кількома кластерами, зберігаючи при цьому єдиний високошвидкісний обчислювальний простір. Також буде доступна версія з кластером з 256 чіпів.
Крім основної лінійки існує ще один спеціалізований чіп Edge TPU, здатний виконувати 4 трильйони операцій на секунду. Це ASIC-чіп, який Google анонсувала ще у 2018 році, щоб запускати моделі машинного навчання (ML) для граничних (Edge) обчислень.
Цей процесор менший за розмірами та, відповідно, споживає суттєво менше енергії у порівнянні з TPU для центрів обробки даних. Ще через рік Edge TPU став доступним для розробників у вигляді лінійки продуктів під брендом Coral.
Як Google використовує чіпи TPU у своїх проєктах
Google є найбільшим споживачем власних TPU-чіпів — як ми згадували раніше, він використовує їх у великій кількості своїх проєктів, та найбільше у Пошуку та Картах. Крім того, модель Gemini 3 навчалася саме на TPU, що допомогло прискорити її тренування та зменшити енергоспоживання порівняно з аналогічними GPU-кластерами.
Хоча техногігант першочергово закриває власні потреби, TPU можна орендувати, хоча і не всім. Наприклад, саме так вчинила компанія Apple — вона хоча і використовувала власні чіпи для донавчання своєї інтелектуальної системи Apple Intelligence, їй все-таки була потрібна допомога Google у вигляді доступу до процесорів TPU.
Близько мільйона таких процесорів отримала і компанія Anthropic – їй вони потрібні, щоб радикально наростити обчислювальні ресурси для моделей Claude. Йдеться про багаторічну угоду на десятки мільярдів доларів, яка має забезпечити понад 1 ГВт потужності вже у 2026 році.
Також відомо, що Meta зараз тестує TPU від Google на обмеженому масштабі, щоб зрозуміти, наскільки вони підходять для її моделей і дата-центрів. За інформацією інсайдерів, компанія обговорює багатомільярдну угоду, яка передбачає оренду потужностей Google Cloud TPU у 2026 році та можливе фізичне встановлення чіпів у власних дата-центрах починаючи з 2027 року.
Broadcom, яка у 2023 році придбала VMware, є партнером Google у розробці та виробництві TPU-чіпів. Саме ця компанія перетворює проєкти Google на реальні мікросхеми для фабрик на кшталт TSMC, проте у власній інфраструктурі Broadcom ці чіпи не використовує. TPU дійсно ще не стали універсальним вибором для всіх — у цієї архітектури є низка обмежень, через які компаній не поспішають масово на неї переходити.
Що стримує масове впровадження TPU
Google позиціонує TPU як ефективнішу альтернативу GPU для частини AI-навантажень, але поки ці чіпи не стали індустріальним стандартом.
Переважно через те, що більшість компаній уже глибоко зав’язана на екосистему Nvidia: їхній код, інфраструктура й інструменти оптимізовані під CUDA, яка працює тільки на GPU Nvidia і не підтримується TPU. Це пояснює високі витрати на міграцію — доведеться адаптувати моделі, пайплайни й MLOps-процеси, а іноді й перебудовувати частину стеку.
Ще один бар’єр — софт і фреймворки: попит ринку давно змістився у бік PyTorch, тоді як історично TPU були адаптовані під TensorFlow, і Google лише останні роки активно наздоганяє в частині підтримки PyTorch.
Це означає, що багато команд не можуть просто взяти наявний PyTorch-код і безболісно перенести його на TPU. До того ж Google залишається досить вибірковим у тому, кому і як дає доступ до TPU, тоді як GPU від Nvidia можна купити чи орендувати у десятків провайдерів.
У результаті навіть ті компанії, що використовують TPU (як от Apple та Anthropic), розглядають ці процесори як доповнення до інфраструктури на базі GPU, тестуючи окремі моделі або нові покоління чіпів.
Як TPU змінили правила гри у навчанні ШІ-моделей
Приблизно за 10 років TPU виросли з «внутрішнього експерименту» Google до однієї з головних стратегічних переваг компанії в перегонах за лідерство у сфері ШІ. Спочатку ці чіпи створювалися, щоб дешевше й ефективніше підтримувати власні продукти, але поступово виросли в повноцінний продукт, доступ до якого можуть отримати інші технологічні гіганти.
А сам Google завдяки кастомним AI-чіпам отримав суттєву перевагу в продуктивності й собівартості навчання моделей, якщо порівнювати з конкурентами, які покладалися лише на GPU Nvidia.
TPU стали одним із ключових факторів, чому на ринку взагалі з’явилася реальна альтернатива «єдиному стандарту» у вигляді GPU й чому великі гравці почали диверсифікувати свої AI-навантаження.
Це не тільки знизило залежність індустрії від одного постачальника, а й пришвидшило інновації: конкуренція в такому випадку допомагає досягти кращої енергоефективності та більшої щільності обчислень.
Підписуйтеся на ProIT у Telegram, щоб не пропустити жодної публікації!