

«Код має бути лаконічним», – скаже будь-який розробник.
Але є винятки. На перший погляд ваш навіть максимально чистий код не завжди можуть зрозуміти інші девелопери. У таких випадках не завадить додати синтаксичного цукру.
Що це за підхід до кодування, як він спрощує роботу та коли ліпше уникати цього прийому, пояснює Сергій Лещенко, Full Stack .NET Software Engineer у команді NIX.
Що таке синтаксичний цукор?
Це синтаксис, який спрощує розуміння наявного функціоналу. Все працюватиме так само, як в аналогічному варіанті коду, без цукру. А далі вже компілятор трансформує «цукрові» рядки у базові функції.
Умовно кажучи, якби без цукру ви б написали 100 рядків коду, а з цукром 50, то компілятор спочатку зробив би з них ті самі 100 рядків, а потім перетворив би їх на машинний код.
Деякі розробники вважають це засміченням коду і проти використання зайвих «підсолоджувачів». Однак за правильного використання цей синтаксис все ж може спростити роботу всієї команди й зробити її ефективнішою.
У моїй практиці були проєкти, де такі можливості мови програмування настільки дивували колег, що розробники забували, що це взагалі цукор, а не окремий функціонал. Тобто якби хтось написав код по-класиці, за правилами «чистоти», це могло б викликати питання.
Навіщо додавати синтаксичний цукор?
Щоб покращити читабельність коду і швидкість його написання. У процесі розробник може застосовувати знайомі йому символи чи слова, навіть із розмовної мови. Це дає змогу скоротити час на написання рутинних елементів та зосередитись, наприклад, на бізнес-логіці.
Пришвидшується і робота команди. Колеги починають краще розуміти ваш код, а отже якісніше опрацьовують пул реквести та легше підхоплюють написані вами фічі. У результаті загальна продуктивність зростає. А це вже оцінять як керівництво проєкту, так і замовники.
Найпростіший приклад синтаксичного цукру – крапка з комою наприкінці рядка
У випадку C# це не цукор, а обов’язковий до використання елемент. Але, скажімо, в JavaScript у ньому немає потреби, оскільки компілятор визначає місце завершення виразу. Тоді крапка з комою виступатиме як цукор. З одного боку елемент є зайвим, та з іншого – покращує читабельність коду. Для багатьох розробників це звичний символ, який дає їм змогу швидше структурувати код.
Тому моя порада: краще завжди використовуйте крапку з комою, щоб девелоперам легше працювалося з вашим кодом, незалежно від їхньої мови програмування. Втім, зі складнішими прикладами «цукрових» елементів не все так просто.
Використання такого синтаксису має два основних ризики:
- Деякий синтаксис схожий на цукор, але ніяк не допомагає. Він лише ускладнює код. Тому, додаючи цукор, подумайте: чи дійсно такий синтаксис піде на користь читабельності.
- Синтаксис схожий на цукор, але має різні задачі. Виглядає так, що елементи дублюють функціонал і відрізняються лише в читабельності. Насправді ж цей синтаксис використовується у різних ситуаціях.
Щойно виходить нова версія мови програмування, я завжди раджу заглянути в Release notes. Там детально описані нововведення та їхні цілі. Наприклад, якісь фічі покращують перфоманс, якісь фактично є синтаксичним цукром. Ніхто не напише, що це саме цукор. Але з опису буде зрозуміло, що такий прийом підвищує читабельність коду.
Трапляються і більш прозорі натяки: коли в Release notes показують, як нова фіча спрощує написання наявного блоку коду. А саме, надаючи приклади, як розробники один і той самий код писали раніше і як тепер його можна зробити лаконічним. Тобто і без цього розробники обходились, але так вдасться працювати швидше.
Як приклад із C# – null coalescing operator. Нічого нового не вносить, тільки заміняє:
if (variable is null)
{
variable = string.Empty;
}Можна написати...
variable ??= string.Empty;... Таким чином код виглядатиме лаконічно.
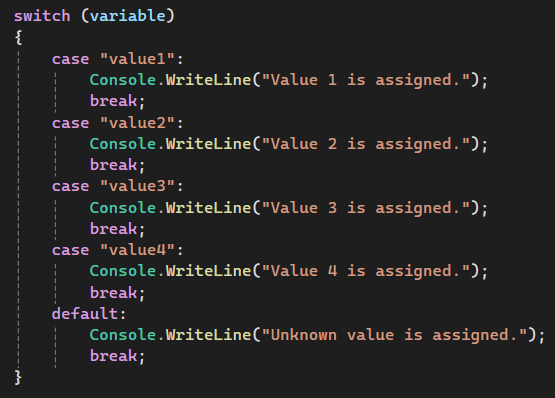
Бувають і складніші випадки. Уявімо кейс із декількома умовами, залежно від яких код виконує різну логіку. Це можна реалізувати за допомогою if/else або ж switch. Здається, що вони дублюють один одного, відрізняється лише кількість коду. Тому один із варіантів ніби-то є цукром. Однак це різні прийоми для різних задач. Варіант з if/else добре працює для списку із двох-трьох кейсів. Для більшої ж кількості краще застосувати switch.
До прикладу, вам необхідно порівняти змінну типу int із конкретним числом. Компілятор сформує switch statement у статичний масив, де буде доволі ефективно порівнюватися фактичне значення змінної з кейсами у світчі. При використанні if/else statement порівнюватися буде кожна умова, допоки не дійде до першої true. Якщо ж порівнювати з рядком, то switch сформує хеш-таблицю, що підвищить швидкість обробки.
Як працює if/else:

Як працює switch:
Уникайте додавання синтаксичного цукру, коли...
На проєкті є свої правила написання коду
Єдиний код стайл значно покращує читабельність проєкту в цілому, спрощує підтримку та розуміння коду. Легше з ним проходить і онбординг нових учасників команди. Тож якщо за код стайлом прописана заборона на синтаксичний цукор або на окремі його зразки, уникайте подібного синтаксису.
Використовуються різні мови програмування
Наприклад, одні працюють із Java, інші – з C#. Тоді код має бути максимально очевидним і прозорим для всіх. Адже синтаксичний цукор, притаманний одній мові програмування, може бути зовсім незрозумілим для «носіїв» іншої. Щоб не заплутатись, намагайтеся працювати без допоміжного синтаксису.
Помітне зловживання «цукром»
Через велику кількість доданих елементів чи рядків розробникам стає складніше розібратися в коді та виокремити функціональні частини. Доведеться бути обережними й знати міру, щоб не страждала читабельність.
Останнє пропоную розглянути на реальному кейсі. Чи не найкраще це ілюструють тернарні оператори. В них одразу видно, що відбувається у коді.
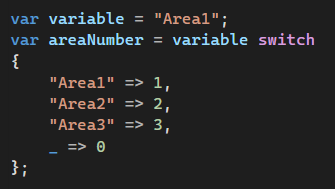
Тернарні оператори чудово зменшують кодову базу: один рядок заміняє умовно 10 рядків із використанням if/else. Інколи у роботі з тернарними операторами у розробників є спокуса використати цю можливість по-максимуму. Наприклад, зробити декілька рівнів вкладеності. Виглядає логічно. Але в реальності, коли одне вираження має три та більше тернарних оператори, девелоперу стає набагато важче читати й осягнути весь масив коду.

У такому випадку краще використати switch-вираження. По своїй суті воно теж сприймається як синтаксичний цукор, але виглядає зрозуміліше:
Інший приклад – global using directives. Можна натрапити на думку, що розробникам вони не подобаються, і на це є декілька причин. По-перше, такі юзінги не дають повної картини. Не зрозуміло, які типи з інших неймспейсів використовуються в кожному файлі. Це збиває з пантелику.
По-друге, при використанні у глобал юзінгах багатьох типів з однаковими статичними членами (наприклад, методами) потрібно явно вказувати тип. Більше того – вписувати юзінг у файл, де цей член використовується. Це також ускладнює розуміння коду. Можете самі оцінити подібний код на прикладі файлу із глобал юзінгом:

Якщо використовувати методи або інші члени типу в інших файлах без написання юзінгу в цьому файлі, а застосовувати глобал юзінги, це призведе до такої проблеми:

Погодьтеся, виглядає занадто складним для розуміння. Хоча ніби все створювалося для підвищення читабельності.
Краще оформити код ось так:
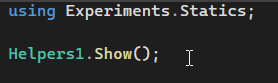
Зауважу, що тут треба вказувати юзінг у потрібному файлі. Використання static-слова в юзінгах допомагає краще працювати зі статичними членами статичного типу, якщо їх надто багато в одному файлі. Без статік юзінгу потрібно було б прописувати назву типу і назву методу. А якщо ще й назва класу задовга, то це призведе до справді важкого для розуміння синтаксису.
З описаним прийомом ви зможете досить ефективно скоротити кодову базу. Без використання глобал юзінгів в окремому файлі код виглядатиме краще:

Додавати чи не додавати синтаксичний цукор – справа розробника. Ви самі маєте розібратися, наскільки це доцільно, чи буде корисно іншим девелоперам на проєкті. Але знати й пам’ятати про перераховані вище ситуації точно варто.
Цукор – не єдина «приправа» для коду. Ще є синтаксична сіль
Це прийом, де в чому схожий на «цукровий». Такий синтаксис теж не додає функціоналу, «солоний» код працюватиме так само, як і «чистий». Але якщо без цукру ви просто довше читаєте код, то без солі зростає ризик виникнення непорозуміння в команді.
На відміну від цукру, сіль не робить код читабельнішим. Кількість символів навпаки збільшується. Але використання солі виправдано тим, що завдяки такому синтаксису розробник точно розуміє, що відбувається, не пропускає деталі та показує іншим девелоперам мету застосованих ним рішень. Загалом це дає змогу знизити вірогідність помилок як автором коду, так і тими, хто працюватиме над продуктом надалі.
Поясню на прикладі. Уявімо чайлд-клас, який походить від базового класу. У цьому чайлд-класі потрібно створити новий член класу, який ховає член базового класу.
З одного боку, не обов’язково додавати до назви нового члену ключове слово new. Програма працюватиме коректно, і новостворений член класу буде використовуватися саме так, як вам потрібно. Але з іншого боку, додавання солі у вигляді слова new дасть змогу всім зрозуміти, що це ховання було явним. Тож не дарма навіть компілятор в C# видасть попередження: «Чи ви впевнені у своєму коді, чи не варто додатково прописати new?».
Як і використання синтаксичного цукру, сіль у коді має свої переваги й недоліки. Додавання деталей часом рятує від помилок. Код гарантовано буде якісним. Певно, це оцінять розробники, у яких багато однотипних задач, коли око, що називається, «замилюється» і можна не помітити важливих дрібниць.
Проте із сіллю треба бути ще обережнішими, ніж із цукром. Складні синтаксичні конструкції в будь-якому випадку впливають на читабельність. Навіть середня кількість елементів робить код нехай і стабільнішим, але все ж складнішим для розуміння, тому практикуйтеся та намагайтеся тримати баланс.
Підписуйтеся на ProIT у Telegram, щоб не пропустити жодної публікації!
Редакція не несе відповідальності за інформацію, викладену у блогах. Це особиста думка автора.