

Microsoft створила нову велику мовну модель, яка може змусити бухгалтерів та аналітиків даних трохи хвилюватися щодо майбутніх перспектив роботи. Про це повідомляє The Stack.
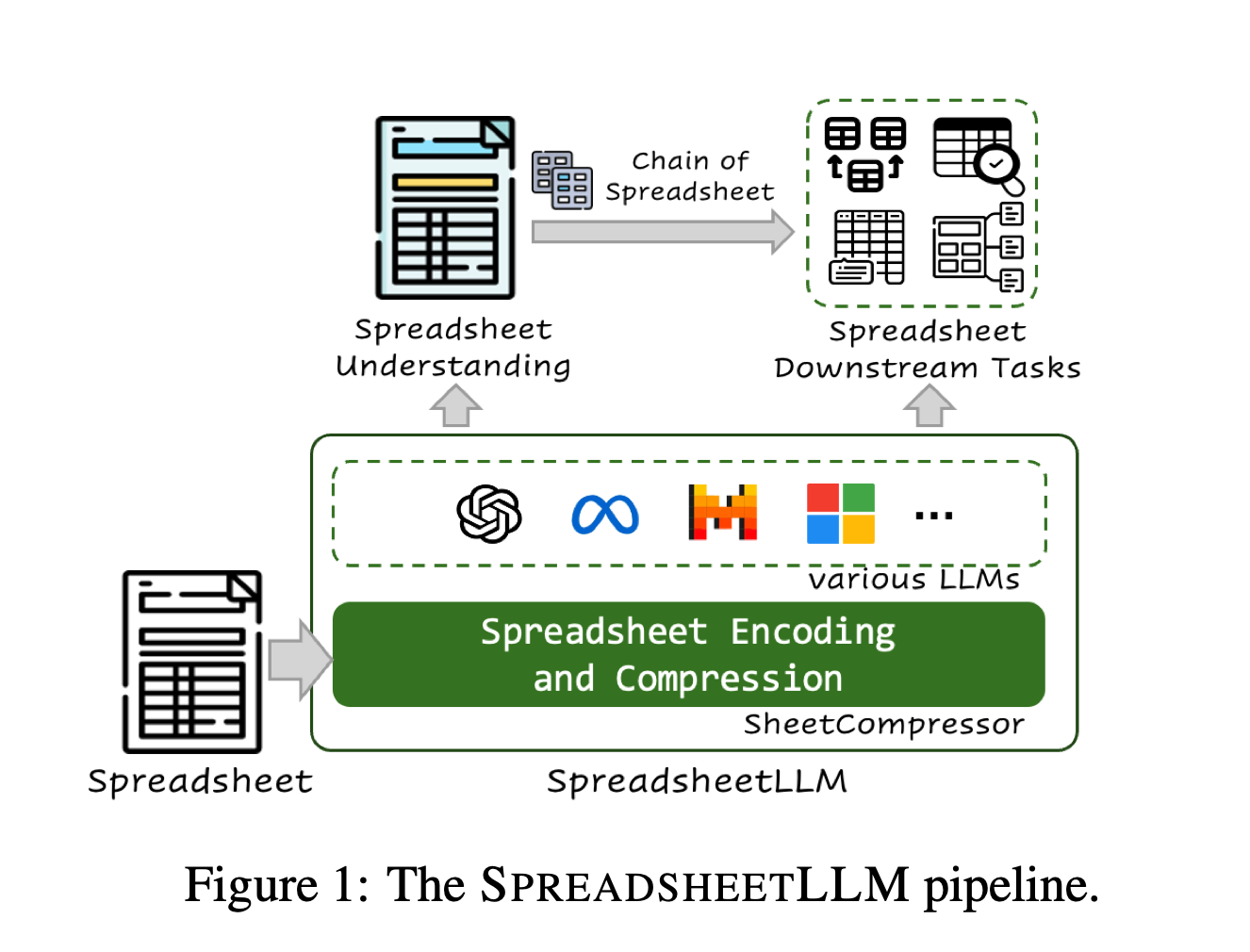
Компанія оприлюднила перші відомості про SpreadsheetLLM — нову модель, яка є високоефективною для різноманітних завдань роботи з електронними таблицями. Стверджується, що вона має потенціал трансформувати керування й аналіз даних електронних таблиць, прокладаючи шлях для більш розумної та ефективної взаємодії з користувачем.
Після того, як наприкінці минулого тижня був тихо опублікований попередній друкований документ про модель, X почав наповнюватися жартами, попереджаючи про те, що «бухгалтери незабаром залишаться без роботи». Один користувач заявив, що «SaaS має серйозні проблеми». Інший написав: «Це буде викликом для світу фінансів».
Поки що LLM були погано оснащені для роботи з електронними таблицями, які характеризуються великими двовимірними сітками, гнучкими макетами та різноманітними параметрами форматування, що створює значні проблеми для великих мовних моделей (LLM).
«У відповідь ми представляємо SpreadsheetLLM — новаторський ефективний метод кодування, призначений для розкриття й оптимізації потужних можливостей LLM для розуміння та міркування в електронних таблицях», — оголосили у компанії.
Боротьба з токенами: новий підхід до електронних таблиць
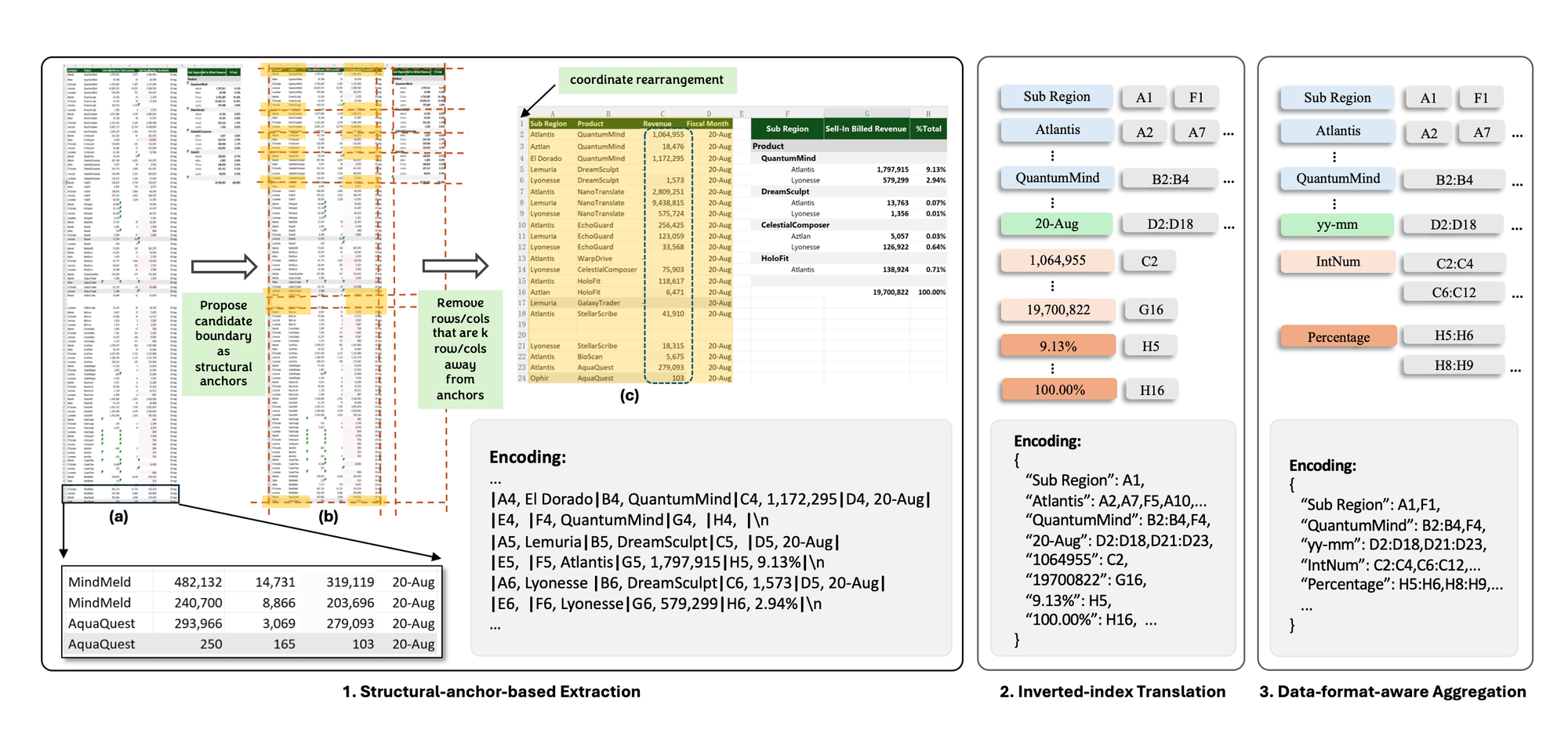
Одна з проблем із використанням LLM в електронних таблицях полягає у тому, що вони загрузають у великій кількості токенів (базових одиниць інформації, які обробляє модель). Щоб вирішити цю проблему, Microsoft розробила SheetCompressor — інноваційну структуру кодування, яка ефективно стискає електронні таблиці для LLM.
«Це значно покращує продуктивність у завданнях виявлення електронних таблиць, перевершуючи базовий підхід на 25,6% у налаштуваннях контекстного навчання GPT4», — додали у Microsoft.
Модель складається із трьох модулів: структурного стиснення на основі прив’язки, зворотного індексного перекладу й агрегації з урахуванням формату даних.
Перший із цих модулів передбачає розміщення так званих структурних якорів по всій електронній таблиці, щоб допомогти LLM краще зрозуміти, що відбувається. Потім він видаляє віддалені однорідні рядки та стовпці, щоб створити згорнуту «скелетну» версію таблиці.
Переклад індексу вирішує проблему, спричинену електронними таблицями з численними порожніми клітинками та повторюваними значеннями, які використовують забагато маркерів.
«Щоб підвищити ефективність, ми відходимо від традиційної серіалізації рядок за рядком і стовпець за стовпцем і використовуємо переклад інвертованого індексу без втрат у форматі JSON. Цей метод створює словник, який індексує непорожні тексти клітинок та об’єднує адреси з ідентичним текстом, оптимізуючи використання маркерів і зберігаючи цілісність даних», — зазначили у Microsoft.
Ще одна перешкода для LLM виникає, коли суміжні числові комірки мають однакові формати чисел.
«Визнаючи, що точні числові значення є менш важливими для розуміння структури електронної таблиці, ми витягуємо рядки числового формату та типи даних із цих клітинок. Потім суміжні комірки з однаковими форматами або типами об’єднуються разом, упорядковуючи розуміння розподілу числових даних без надмірних символічних витрат», — йдеться у повідомленні.
Після проведення всебічної оцінки методу на різноманітних LLMs фахівці Microsoft виявили, що SheetCompressor зменшує використання маркерів для кодування електронних таблиць на 96%.
Новий LLM базується на методології Chain of Thought, щоб представити структуру під назвою Chain of Spreadsheet (CoS), яка може «розкладати» міркування електронної таблиці на конвеєр таблиць виявлення-збіг-міркування.
«Chain of Spreadsheet, розширення інфраструктури для подальших завдань електронної таблиці, ілюструє його широке застосування і потенціал для трансформації керування й аналізу даних електронних таблиць, прокладаючи шлях для більш розумної та ефективної взаємодії з користувачем», — заявили у корпорації.
Читайте також на ProIT: Великий SQL-практикум українською для дата-аналітиків. Новачкам і світчерам підготуватися!
Підписуйтеся на ProIT у Telegram, щоб не пропустити жодної публікації!