

Чат-боти, такі як ChatGPT, Claude.ai і phind, можуть бути дуже корисними, але ви можливо не завжди хочете, щоб ваші запити або чутливі дані оброблялися зовнішньою програмою. Це особливо правильно на платформах, де вашу взаємодію можуть перевіряти люди та іншим чином використовувати для навчання майбутніх моделей.
Одне з рішень – завантажити велику мовну модель (LLM) і запустити її на власному комп’ютері. Таким чином стороння компанія ніколи не матиме доступу до ваших даних.
Це також можливість спробувати деякі нові спеціальні моделі, такі як нещодавно оголошена Meta сімейство моделей Code Llama, які налаштовані для кодування, і SeamlessM4T, призначені для перетворення тексту в мовлення та мовного перекладу.
Керувати власним LLM може здатися складним, але з потрібними інструментами це напрочуд легко. І вимоги до обладнання для багатьох моделей не є божевільними.
InfoWorld протестував параметри, представлені у цій статті, на двох системах: ПК Dell із процесором Intel i9, 64 ГБ оперативної пам’яті та графічним процесором Nvidia GeForce 12 ГБ (який, імовірно, не використовувався для роботи з більшою частиною цього програмного забезпечення), а також на Mac із чипом M1, але лише 16 ГБ оперативної пам’яті.
Майте на увазі, що може знадобитися невелике дослідження, щоб знайти модель, яка досить добре справляється з вашим завданням і працює на апаратному забезпеченні вашого ПК.
Варто також зазначити, що моделі з відкритим кодом, ймовірно, продовжуватимуть удосконалюватися, тож деякі експерти очікують, що розрив між ними та комерційними лідерами скоротиться.
Запустіть локальний чат-бот за допомогою GPT4All
Якщо вам потрібен чат-бот, який працює локально та не надсилає дані кудись, GPT4All пропонує клієнт для ПК, який досить легко налаштувати. Він містить варіанти для моделей, які працюють у вашій системі, а також є версії для Windows, macOS та Ubuntu.
Коли ви вперше відкриєте настільну програму GPT4All, ви побачите варіанти завантаження приблизно 10 (на момент написання цієї статті) моделей, які можна запускати локально. Серед них чат Llama-2-7B, модель від Meta AI.
Також можна налаштувати GPT-3.5 і GPT-4 OpenAI (якщо у вас є доступ) для нелокального використання, якщо у вас є ключ API.
Частина завантаження моделі інтерфейсу GPT4All спочатку була трохи заплутаною.
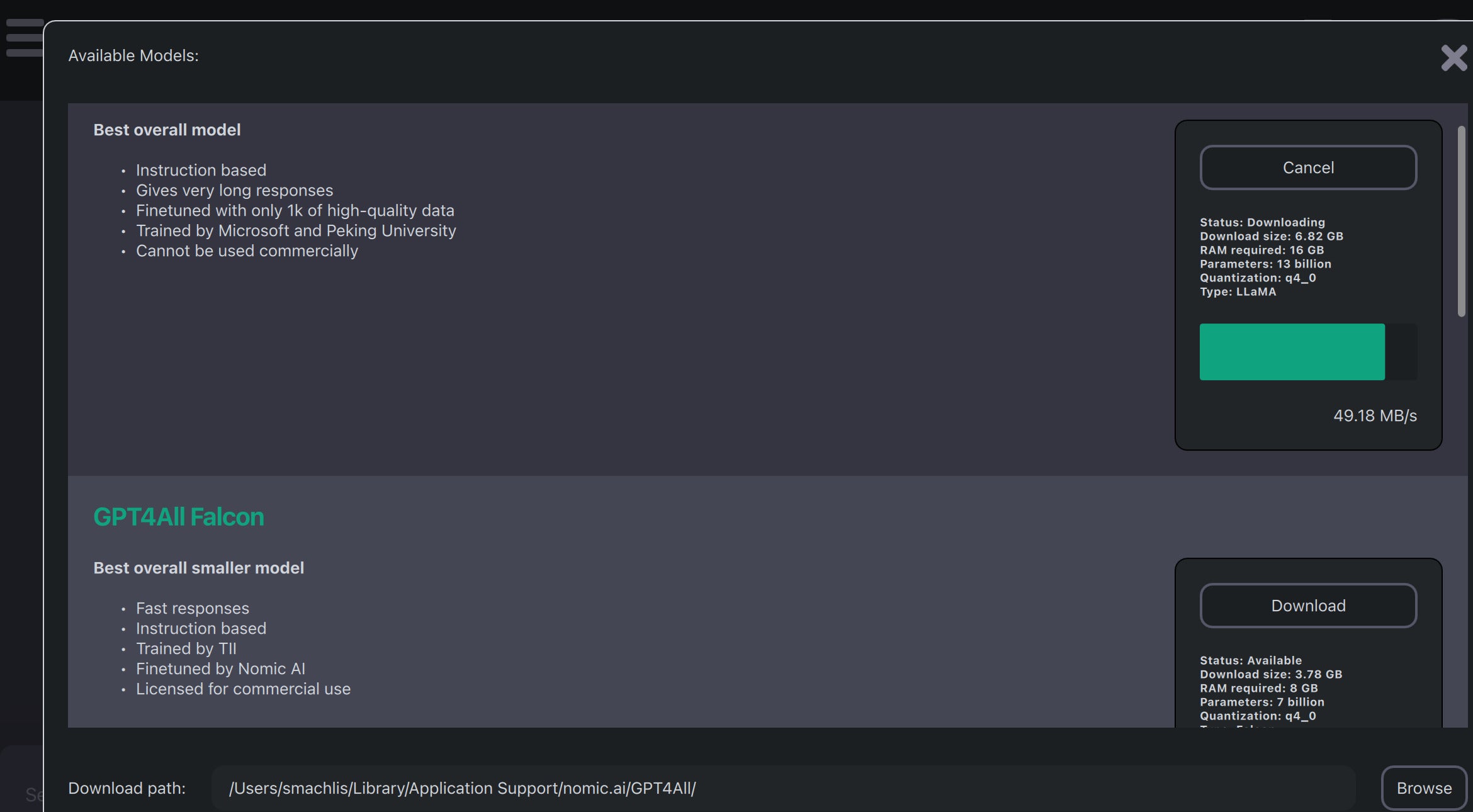
Після налаштування моделей інтерфейс чат-бота стає зрозумілим і простим у використанні. Зручні опції включають копіювання чату в буфер обміну та створення відповіді.
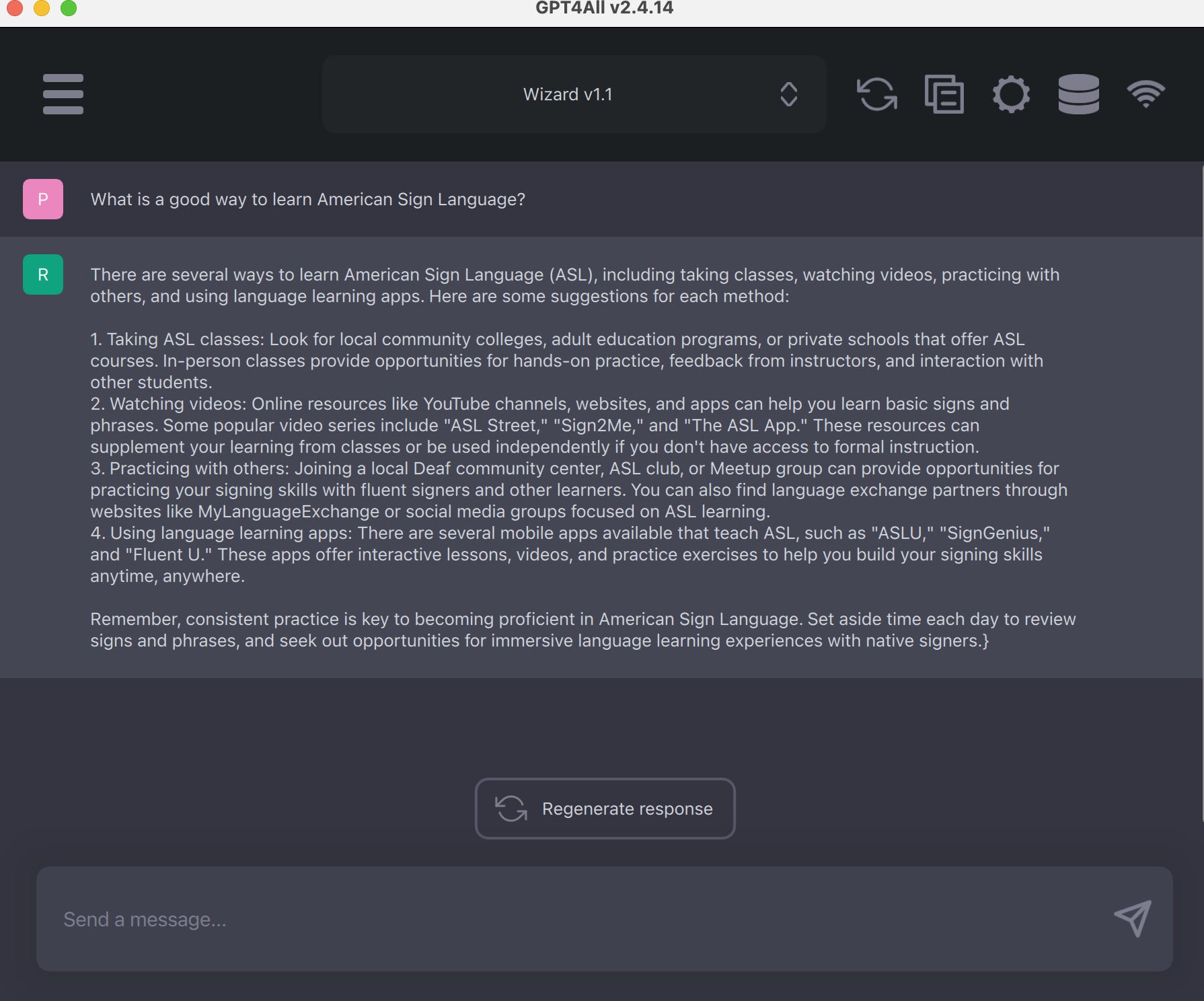
Інтерфейс чату GPT4All зрозумілий і простий у використанні.
Існує також нова бета-версія плагіна LocalDocs, яка дозволяє «спілкуватися» з вашими документами локально. Ви можете увімкнути його на вкладці Settings > Plugins, де побачите заголовок «Налаштування плагіна LocalDocs (бета-версія)» та можливість створити колекцію за певним шляхом до папки.
Розробка над плагіном триває, і документація попереджає, що LLM все ще може «галюцинувати» (вигадувати), навіть якщо він має доступ до доданої вами експертної інформації. Тим не менш, це цікава функція, яка, ймовірно, покращиться, коли моделі з відкритим кодом стануть більш спроможними.
Крім програми чат-бота, GPT4All також має прив’язки для Python, Node й інтерфейс командного рядка (CLI). Існує також режим сервера, який дає змогу взаємодіяти з локальним LLM через HTTP API, структурований дуже схожий на OpenAI.
Мета полягає у тому, щоб ви могли замінити локальний LLM на OpenAI, змінивши пару рядків коду.
LLM у командному рядку
LLM від Саймона Віллісона – це один із найпростіших способів завантаження та використання програми LLM з відкритим кодом локально на вашій машині. Хоча для його запуску потрібно встановити Python, вам не потрібно будь-якого коду Python. Якщо ви користуєтеся Mac і використовуєте Homebrew, просто встановіть за допомогою:
brew install llmЯкщо ви користуєтеся Windows, скористайтеся улюбленим способом інсталяції бібліотек Python, наприклад:
pip install llmLLM за замовчуванням використовує моделі OpenAI, але ви можете використовувати плагіни для запуску інших моделей локально. Наприклад, якщо ви встановите плагін gpt4all, то матимете доступ до додаткових локальних моделей від GPT4All.
Крім того, є плагіни для llama, проєкту MLC і MPT-30B, а також додаткові дистанційні моделі.
Встановіть плагін у командному рядку за допомогою llm install model-name:
llm install llm-gpt4allВи можете переглянути всі доступні моделі – дистанційні й ті, які ви встановили, включно з короткою інформацією про кожну, за допомогою команди: llm models list.

Дисплей, коли ви просите LLM надати список доступних моделей.
Щоб надіслати запит до локального LLM, використовуйте синтаксис:
llm -m the-model-name "Your query"Виберіть правильний LLM
Як вибрати модель? Одним із джерел є 14 LLM, хоча вам потрібно буде перевірити, які з них можна завантажити та чи сумісні вони з плагіном LLM.
Також можна перейти на домашню сторінку GPT4All і прокрутити вниз до Model Explorer для моделей, які сумісні з GPT4All. Варіант falcon-q4_0 – це відносно невелика модель з ліцензією, що дозволяє комерційне використання.
InfoWorld поставив запитання, схоже на ChatGPT, не видаючи окремої команди для завантаження моделі:
llm -m ggml-model-gpt4all-falcon-q4_0 "Tell me a joke about computer programming"Це одна річ, яка робить роботу користувача LLM елегантною: якщо модель GPT4All не існує у вашій локальній системі, інструмент LLM автоматично завантажує її для вас перед виконанням запиту. Під час завантаження моделі ви побачите індикатор прогресу в терміналі.
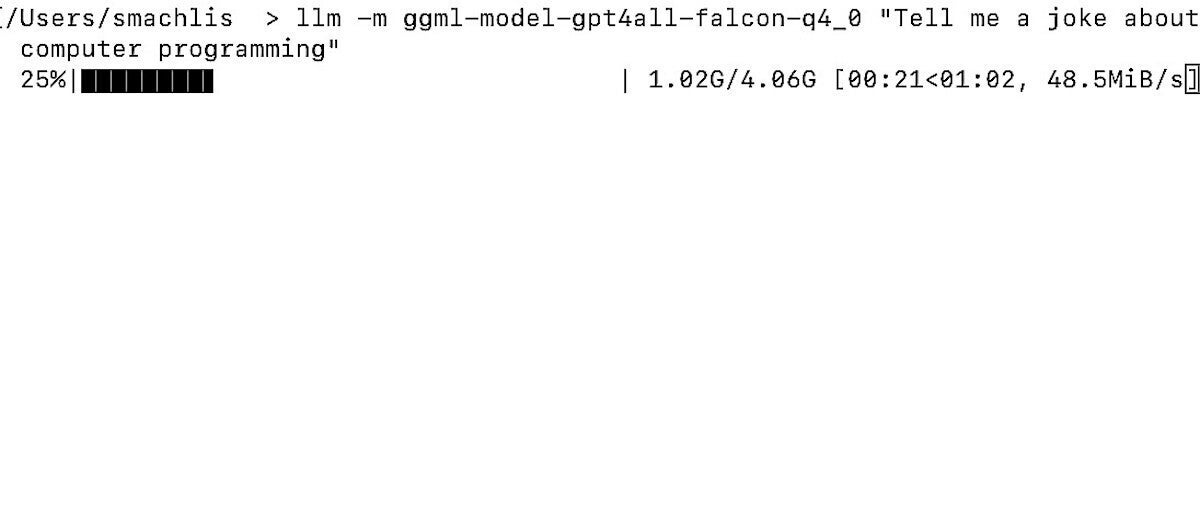
LLM автоматично завантажив модель, яку я використав у запиті.
Ви також можете встановити псевдоніми для моделей у межах LLM, щоб мати змогу звертатися до них за коротшими іменами:
llm aliases set falcon ggml-model-gpt4all-falcon-q4_0Щоб переглянути всі доступні псевдоніми, введіть: llm aliases.
Плагін LLM для моделей Meta Llama вимагає трохи більше налаштувань, аніж GPT4All. Прочитайте подробиці в репозиторії GitHub плагіна LLM.
Зауважте, що llama-2-7b-chatвдалося запустити на Mac з чіпом M1 Pro і лише 16 ГБ оперативної пам’яті. Він працював досить повільно порівняно з моделями GPT4All, оптимізованими для менших машин без GPU.
LLM має інші функції, наприклад прапорець argument, який дозволяє продовжити з попереднього чату, і можливість використовувати його у сценарії Python.
На початку вересня програма отримала інструменти для генерації вбудованих текстів, числові представлення значення тексту, які можна використовувати для пошуку пов’язаних документів. Ви можете побачити більше на вебсайті LLM.
Віллісон, співавтор популярного фреймворку Python Django, сподівається, що інші члени спільноти внесуть більше плагінів в екосистему LLM.
Моделі Llama на Mac: Ollama
Ollama – це ще простіший спосіб завантаження та запуску моделей, ніж LLM, хоча він також більш обмежений. Зараз у нього є версія для macOS і Linux; його творці кажуть, що підтримка Windows «незабаром з’явиться».
Налаштувати Ollama надзвичайно просто.
Встановлення відбувається через елегантний інтерфейс за допомогою вказування та клацання. І хоча Ollama є інструментом командного рядка, існує лише одна команда із синтаксисом ollama run model-name. Як і в LLM, якщо моделі ще немає у вашій системі, вона завантажиться автоматично.
Ви можете переглянути список доступних моделей на https://ollama.ai/library, який на момент написання цієї статті включав кілька версій моделей на основі Llama, таких як Llama загального призначення 2, Code Llama, CodeUp від DeepSE, налаштований для деякі завдання з програмування та medllama2, який було налаштовано, щоб відповідати на медичні запитання.
README репозиторію Ollama GitHub містить корисний список специфікацій деяких моделей і поради щодо того, що «ви повинні мати щонайменше 8 ГБ оперативної пам’яті для запуску моделей 3B, 16 ГБ для запуску моделей 7B і 32 ГБ для запуску моделей 13B».
На моєму Mac із 16 ГБ оперативної пам’яті продуктивність 7B Code Llama була напрочуд швидкою. Він відповість на запитання про команди оболонки bash/ zsh, а також мови програмування, такі як Python і JavaScript.
Як виглядає запуск Code Llama у вікні терміналу Ollama.
Незважаючи на те, що це була найменша модель у сімействі, вона добре, але не ідеально відповіла на запитання про кодування R: «Напишіть код R для графіка ggplot2, де смуги сталевого синього кольору».
Код був правильним, але дуже довгим, і попередній кодовий фрагмент був такий самий, як із попереднього запиту. Тобто було видно, що модель використовувала інформацію з попереднього запиту.
Ollama має деякі додаткові функції, такі як інтеграція LangChain і можливість працювати з PrivateGPT, які можуть бути неочевидними, якщо ви не перевірите сторінку посібників репо GitHub.
Якщо ви користуєтеся Mac і хочете використовувати Code Llama, то можете запустити його у вікні терміналу та відкривати його щоразу, коли у вас виникне питання.
Спілкуйтеся в чаті з вашими власними документами: h2oGPT
H2O.ai вже деякий час працює над автоматизованим машинним навчанням, тому цілком природно, що компанія перейшла в чатовий простір LLM. Деякі з його інструментів найкраще використовувати людям із досвідом, але інструкції щодо встановлення тестової версії програми для настільного комп’ютера чату h2oGPT були швидкими та простими навіть для новачків у машинному навчанні.
Ви можете отримати доступ до демоверсії в Інтернеті (не використовуючи LLM локально для вашої системи) на gpt.h2o.ai, що є корисним способом дізнатися, чи подобається вам інтерфейс, перш ніж завантажувати його у свою власну систему.
Для локальної версії: клонуйте репозиторій GitHub, створіть і активуйте віртуальне середовище Python і запустіть п’ять рядків коду, знайденого у файлі README.
Згідно з документацією, результати дають вам «обмежену можливість запитань і відповідей на документи» та одну з моделей Meta Llama, але вони працюють. Ви матимете версію моделі Llama, завантажену локально, і програму, доступну за адресою: http://localhost:7860 під час виконання одного рядка коду:
python generate.py --base_model='llama' --prompt_type=llama2
Локальна модель LLaMa відповідає на запитання на основі документації VS Code.
Не додаючи власні файли, ви можете використовувати програму як загальний чат-бот. Або можете завантажити деякі документи та поставити запитання щодо цих файлів.
Сумісні формати файлів включають PDF, Excel, CSV, Word, текст, markdown тощо. Тестовий застосунок добре працював на Mac 16 ГБ, хоча результати меншої моделі не можна порівняти з платним ChatGPT із GPT-4 (як завжди, це функція моделі, а не програми).
Інтерфейс користувача h2oGPT пропонує вкладку «Експерт» із низкою параметрів конфігурації для користувачів, які знають, що вони роблять. Це дає більш досвідченим користувачам можливість спробувати покращити свої результати.
Вивчення вкладки «Експерт» у h2oGPT.
Якщо вам потрібно більше контролю над процесом і параметрами для більшої кількості моделей, завантажте повну програму, хоча може знадобитися більше роботи, щоб запустити модель на обмеженому апаратному забезпеченні.
У файлі README є інструкції зі встановлення для Windows, macOS і Linux.
Роб Мулла, який зараз працює в H2O.ai, опублікував на своєму каналі YouTube відео про встановлення програми на Linux. Хоча відео завантажене вже кілька місяців тому, й інтерфейс користувача програми, здається, змінився, у відео все ще є корисна інформація, зокрема корисні пояснення щодо H2O.ai LLM.
Легкий, але повільний чат із вашими даними: PrivateGPT
PrivateGPT також розроблено, щоб дозволити вам надсилати запити до власних документів природною мовою й отримувати генеративну відповідь ШІ.
Документи в цій програмі можуть включати кілька десятків різних форматів. І README запевняє вас, що дані «на 100% конфіденційні, жодні дані не залишають ваше середовище виконання в будь-якому місці. Ви можете завантажувати документи та ставити запитання без підключення до Інтернету!»
Читайте також на ProIT: Meta та Microsoft випускають Llama 2 – мовну модель ШІ для комерційного використання.
Підписуйтеся на ProIT у Telegram, щоб не пропустити жодну публікацію!