

Вебскрейпінг – це процес отримання структурованих вебданих. Де знадобиться вебскрейпінг? Від моніторингу новин до аналізу цін у магазинах – це може бути будь-що.
Якщо ви коли-небудь копіювали із сайту інформацію та переносили її до таблиць чи інших типів сховищ, то фактично теж займалися скрейпінгом.
Вручну збирати дані складно і довго. Набагато простіше довірити це завдання скрейперу – програмі, яка автоматизує цей процес. Поки ви самотужки виписуєте один товар з онлайн-магазину, програма здатна витягти кілька сотень таких найменувань і структурувати їх у базі даних.
І хоча у цій статті ми зосередимось на скрейпінгу, зауважу, що це не єдиний спосіб збору даних. Існують й альтернативи.
Як ще можна отримувати вебдані
- Через API – набір протоколів зв’язку, які забезпечують доступ до даних програми, операційної системи або інших сервісів переважно у форматі JSON.
Доступ через API надається розробникам інших сайтів або застосунків, які використовують ті ж самі дані, щоб їм не довелося проводити своїх досліджень. Наприклад, сервіс прогнозу погоди може створити API, щоб розробники іншого сервісу збирали, аналізували й інтегрувати дані про погоду у свої програми.
Такий доступ до інформації може бути платним або безоплатним, вільним або з обмеженою кількістю запитів за певний проміжок часу. Тому в деяких проєктах використання API для збору даних не підходить. Ба більше: сервіс у принципі не зможе відкривати свій API.
- Через інструменти автоматизації – програми на кшталт Selenium. Взагалі-то вони створені не для скрейпінгу, а для тестування. Але все одно дозволяють отримувати дані, бо імітують процес взаємодії користувача із браузером.
Цей варіант, звісно, спрацює, але його краще залишити наостанок, якщо виникли проблеми з іншими варіантами. Для повноцінної роботи з такими програмами потрібно буде окремо розібратися в налаштуваннях, інсталювати драйвер браузера тощо.
Також важливим є те, що вилучення даних у такому випадку буде обмежене функціонально. Зокрема, немає повноцінних пайплайнів та постобробки даних, як у фреймворках для скрейпінгу. Проте в деяких випадках без цих інструментів не обійтися. Наприклад, якщо у вас немає доступів до API й при цьому є проблеми з отриманням контенту сторінки за допомогою скрейперів.
Обираючи між вебскрейпінгом, роботою з API та інструментами автоматизації, я рекомендую врахувати такі кроки:
- Перевірити наявність та адекватність API. Цей варіант – найпростіший. Дані вже будуть зібрані, структуровані й очищені. У цьому випадку достатньо просто взаємодіяти з набором ендпоінтів, витягувати дані та далі маніпулювати ними, як вам заманеться. А далі залишиться лише зберігати результати у базу даних чи інше сховище. Все організовано швидко і зручно.
- Використовувати скрейпери. Якщо немає змоги працювати з API, запускайте вебскрейпінг. Створені для цього бібліотеки та фреймворки заточені під отримання максимуму даних за мінімум часу. Щоправда, недостатньо просто натиснути кнопку. Слід проаналізувати сайт та зробити додаткову обробку даних для їх зберігання. Це довше, ніж робота з API, але швидкість збору даних все одно доволі висока.
- Вмикати інструменти автоматизації. Тільки якщо перші два підходи не спрацювали. Інструменти автоматизації не надто зручні та швидкі для подібних задач, однак виручать, якщо інші засоби не допомогли отримати необхідні дані.
Що краще: Xрath чи CSS?
Xpath і CSS-селектори – це мови, які дають змогу описати необхідні для вилучення елементи. Їх також можна називати стратегіями локатора.
CSS, або каскадні таблиці стилів, – це мова таблиць стилів для опису зовнішнього вигляду та форматування документа, написаного в HTML або XML.
Якщо CSS – це шаблони для вибору стилізованих елементів, то Xpath – це мова шляхів XML та мова запитів для вибору вузлів із XML-документа. Xpath використовує вирази шляху для навігації за елементами й атрибутами в XML-документі.
Основна перевага CSS-селекторів – зручний синтаксис. Вони добре підходять для простих задач.
Хоча мають і низку обмежень:
- При використанні селекторів неможливо шукати елементи за вкладеними умовами типу «і» й у яких ще є подвійний «або».
- Не можна звертатися до батьківських елементів та елементів, які знаходяться на одному рівні вкладеності з вашим, але до яких немає прямого доступу.
- Не вдасться шукати тег за його вмістом. Тобто за текстом чи іншим контентом.
Тому інколи застосування CSS-селекторів може бути недостатнім. Попри більш навантажений синтаксис Xpath дозволяє виконувати все, з чим є проблеми у селекторів CSS.
Однак час від часу зустрічається думка, що CSS працює швидше, ніж Xpath. Зі свого досвіду скажу так: різниця на користь CSS є, але зазвичай вона несуттєва. Це зокрема залежить від складності виразу, від того, чи використовуються для доступу до ресурсу проксі або VPN тощо. Тож вибір між Xpath і CSS – це вибір між функціоналом і зручністю.
lxml/BeautifulSoup/Scrapy
Коли ви розібралися з базовими поняттями парсингу, можна перейти до інструментів, які використовуються в Python. Це 3 основних інструменти: lxml, BeautifulSoup і Scrapy.
Перші – схожі бібліотеки, але з різними на момент їх створення підходами. lxml був зосереджений на роботі з Xpath, а BeautifulSoup – із CSS-селекторами. Остання бібліотека була створена для роботи зі зламаними HTML-документами.
На сьогодні різниця між lxml та BeautifulSoup зведена майже до нуля: їхній синтаксис та функціонал дуже схожі. Обидві бібліотеки дають змогу використовувати двигун конкурента як двигун, що підключається.
Я б рекомендував застосовувати бібліотеки лише у двох випадках. Перший – коли обсяг парсингу невеликий. Другий – за умови, що вилучення даних не є основним пріоритетом системи. В такому випадку можна додати Python-модуль із парсером і використовувати ці дві бібліотеки.
Але якщо плануєте збирати дані з тисяч сторінок або переходити між безліччю сторінок, поєднаних кроспосиланнями, і створювати пайплайни для обробки отриманих даних, тоді краще вибрати Scrapy. Він часто використовується у великих проєктах, де треба ізолювати код скрейпера від решти системи.
Та зауважте: Scrapy має обмеження на структуру дерева проєкту, оскільки в нього свої файлова структура та конфігураційні файли.
Бібліотеки для вебскрейпінгу
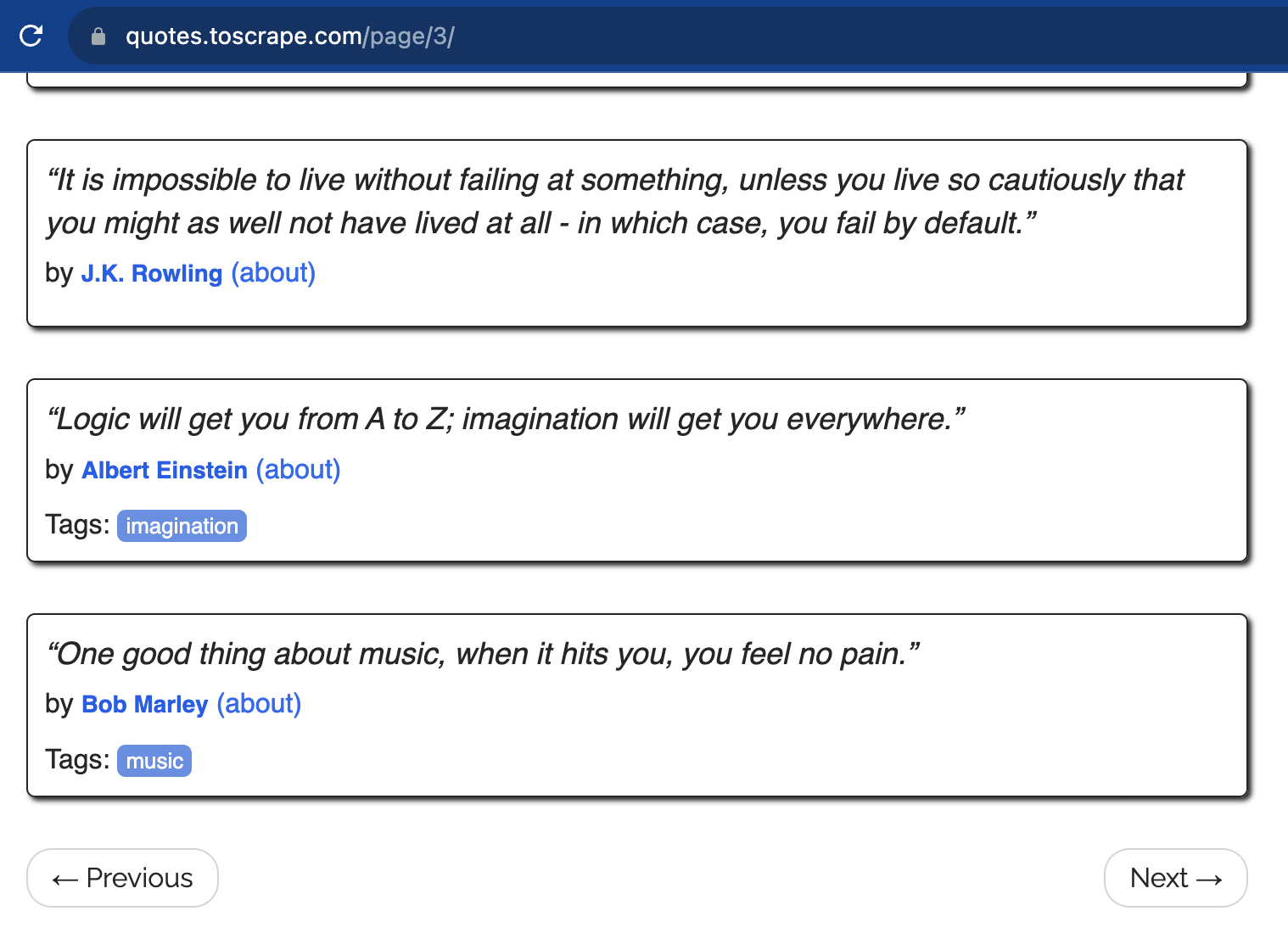
Почнімо із lxml та BeautifulSoup. Щоб потренувати навички парсингу, скористуйтеся Quotes to Scrape. Тут зібрані цитати відомих людей. Цей сайт дозволяє скрейпити, використовувати переходи по сторінках, отримувати додаткову інформацію про авторів тощо. Завдяки тому, що цей сервіс створений саме для тренування вебскрейпінгу, у його сторінок нормальна структура із зазначенням повноцінних класів, ID та іншого.
Для початку слід встановити бібліотеки BeautifulSoup та lxml способом, звичним для вас: чи то використовуючи pip install, чи то використовуючи інтерфейс для менеджменту пакетів у вашій IDE.
Після цього переходимо до функціоналу бібліотек. Насамперед необхідно отримати контент сторінки. Все це виконується через звичайний request.get, у який передамо посилання на потрібний ресурс.
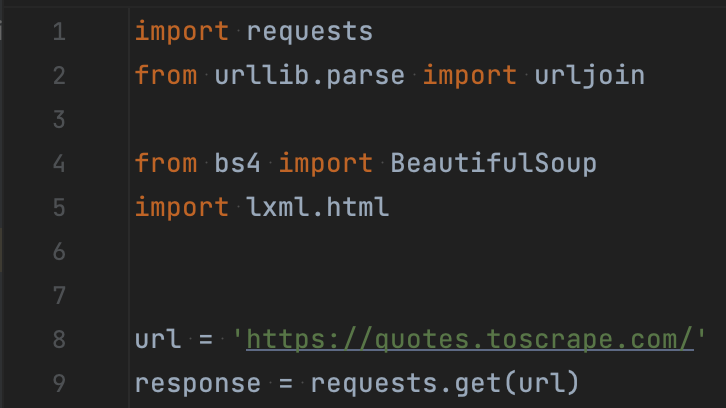
Далі залишається лише закинути все це в soup, щоб отримати мінімальний набір інформації. Ми створюємо новий обʼєкт BeautifulSoup, передаємо в нього response.text і вказуємо бажаний синтаксис для обробки даних зі сторінки (наприклад, формат lxml). Після цього просто відобразимо наш об’єкт звичайною командою print().

У результаті отримаємо ту ж сторінку, але у вигляді тегів.
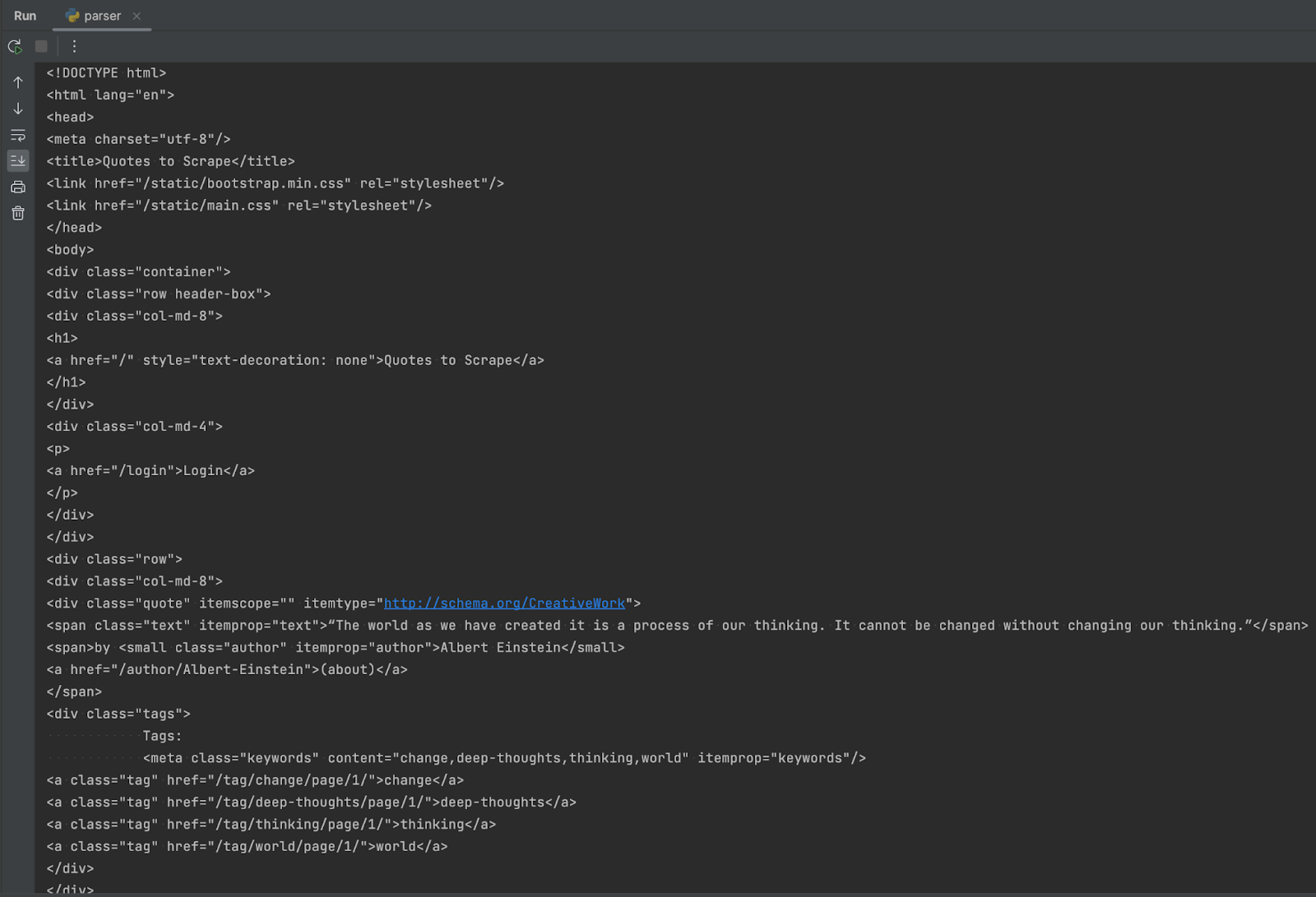
Можна зіставити отриманий документ із самим сайтом. Для цього треба зробити Inspect Element на потрібному об’єкті вебсторінки й отримати по суті ті самі дані, але краще відформатовані.
Безпосередньо HTML-код краще ніж нічого, але цього замало. Тому треба витягти з файлу необхідну інформацію. У цьому випадку – цитати, їхніх авторів і теги.

Наприклад, для отримання авторів варто вивчити сам сайт і зрозуміти, як на ньому описуються такі дані. Тут ця інформація зберігається за допомогою тегу small із доданим класом author.
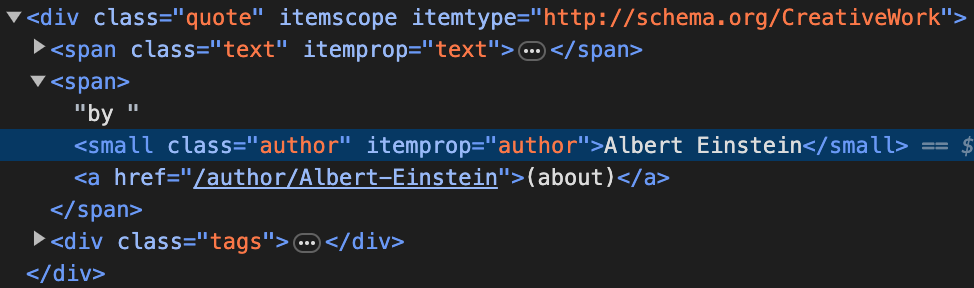
Аналогічно, зі скріншота вище можна побачити, що для цитат використовується div із класом quote. І залишаються теги. У них це все оформляється як div, всередині якого є посилання (тег a) із класами tags і tag відповідно.
Цю інформацію слід перенести до коду. Тобто дати BeautifulSoup команду знайти всі елементи з таким тегом або таким набором тегів із певним класом. У цьому випадку це класи text, author та tags, як зазначено вище. Тож для перевірки виведемо цитати й на цьому зупинимо програму.

Результат кращий за попередній. Наприклад, видно, що було отримано Python-список із цитатами. Але є нюанс. Це ще не цитати, а об’єкти HTML (точніше span). Тобто фактично перед нами метаінформація, хоча потрібен лише контент тегів.
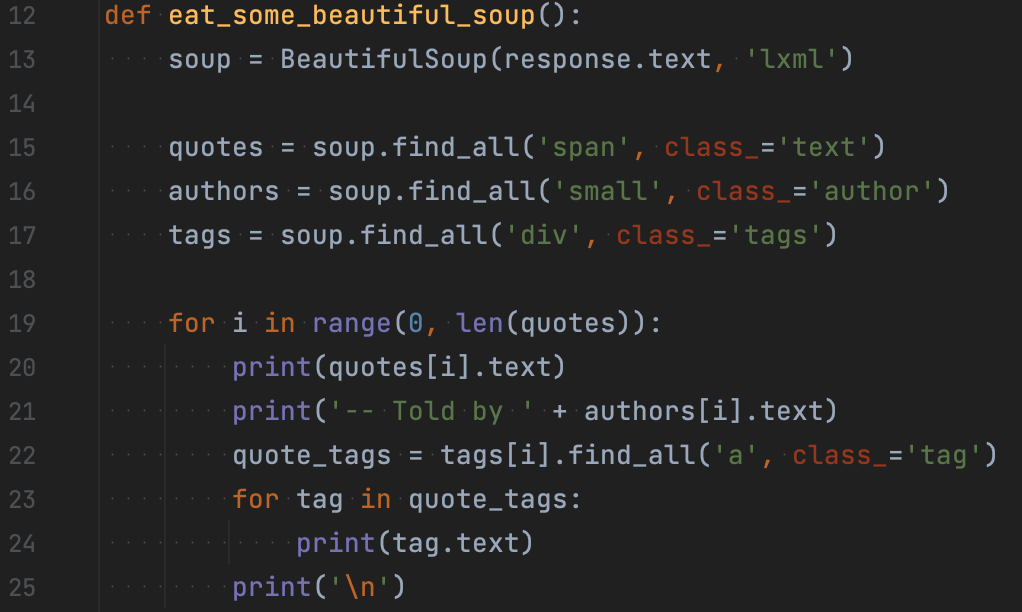
Тому слід трансформувати отримані дані за допомогою вбудованих засобів Python. Для цього треба пройтися циклом по отриманих елементах цитат, авторів і тегів та витягнути кожен конкретний об’єкт.

Для тегів необхідно зробити додаткову проходку серед кожного div-елемента, що містить усі теги. А щоб отримати текст потрібного об’єкта, знадобиться атрибут text. На наступному зображені показано повну версію коду.
Запускаємо й отримуємо всі цитати в лапках, із зазначеними авторами та набором тегів для них. Остання цитата у списку: «A day without sunshine is like, you know, night».
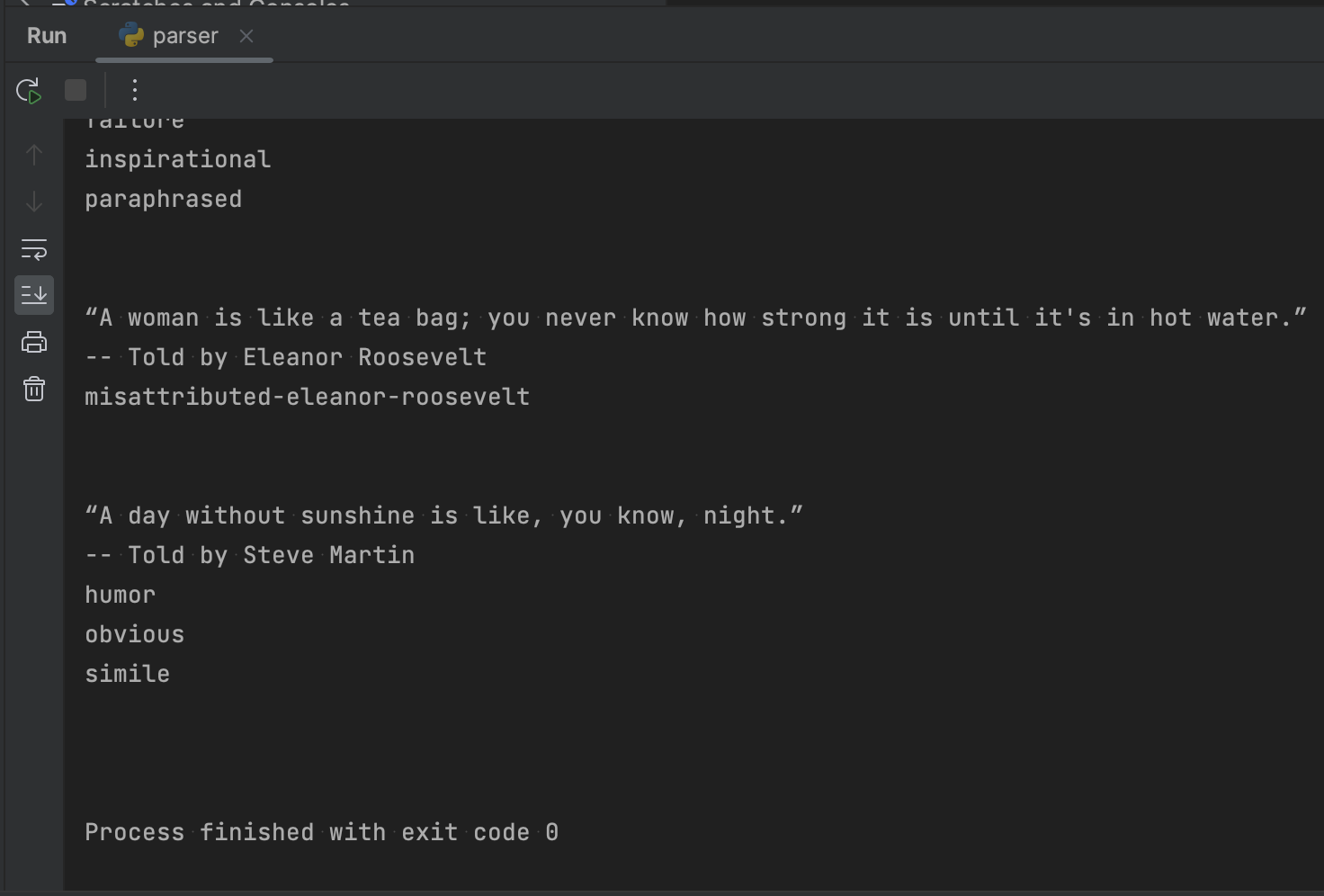
Звіряємо із сайтом – все правильно! Тобто результат знову покращено. Але радіти зарано.

По-перше, дані отримані лише з однієї сторінки. По-друге, парсити дані все ще досить незручно. А ще важливо звернути увагу, що тут не було жодних зав’язок об’єктів один на одного. Нерідко трапляються ситуації, коли пошук елементів може відбуватися лише в певному порядку, бо потрібно знайти теги-нащадки або навпаки батьківські.
Як за допомогою бібліотек парсити кілька сторінок
Почну із простого завдання – пейджинг. Для цього прикладу звернемося до другої згаданої бібліотеки lxml і водночас подивимось на синтаксис XPath.
У цьому випадку трохи збільшується кількість функцій, але суть залишається простою. Тут є функція для читання, скажімо, трьох перших сторінок. HTML отримуємо через той же response.text, що і в попередньому прикладі. Різниця починається в командах: замість beautifulsoup використаємо lxml.html.fromstring.
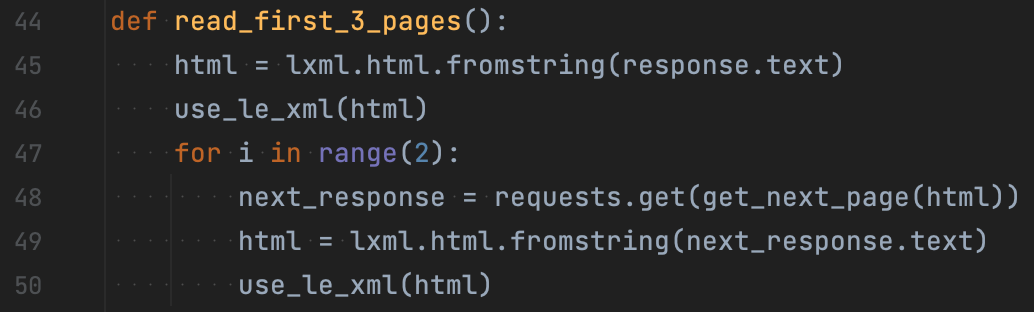
Нам потрібна функція, яка безпосередньо парсить сторінку. У цьому випадку це буде функція use_le_xml(html). Поки пропустимо її контент, а подивимося далі. Через необхідність читання перших трьох сторінок ми робимо відповідний цикл. Всередині нього будемо знаходити посилання на наступну сторінку, переходити, обробляти та шукати наступну сторінку від нової «поточної».
Далі перейдемо безпосередньо до функції переходу на наступну сторінку, get_next_page. Спочатку заходимо на сайт і робимо Inspect Element для кнопки Next. Завдяки цьому можна побачити, що вона розміщена у простій таблиці HTML з ul-елементом та a href.
Наступний крок – використаємо команду html.find(). Її основна відмінність від findall в тому, що вона знаходить саме перший елемент, який задовольняє описані критерії тега. Але якщо ви хочете використовувати саме findall, то потрібно наприкінці дописати індекс елемента, щоб отримати лише його, а не повний список елементів.
Погляньмо уважніше на цей код. Тут клас вказується не через нотацію функції, а через вираз xpath. Якщо вираз починається не з «.», а з «//», то пошук йде по всій сторінці. В нашому ж випадку пошук виконається з певного місця, яке вказано у змінній html. Фактично це просто вказує lxml, із якого елемента дерева тегів треба починати пошук. Можна передати як всю сторінку, так і фрагмент. Наприклад, один div.

Використання подвійного слешу дає вказівку, що можна відійти від поточного елемента вглиб на кілька рівнів, а не на один. У моєму прикладі є початковий елемент nav, від якого відбувається пошук по сторінці. Всередині нього є тег ul, який зі свого боку містить тег li.
Через те, що нас не цікавлять дані додаткові теги, ми просто пропускаємо їх, коли пишемо шлях до потрібного елемента, вказуючи “//” та конкретизуємо потрібний нам тег за допомогою класу next.
У результаті отримуємо посилання на наступну сторінку. Але воно не повне – це просто /page/2/.
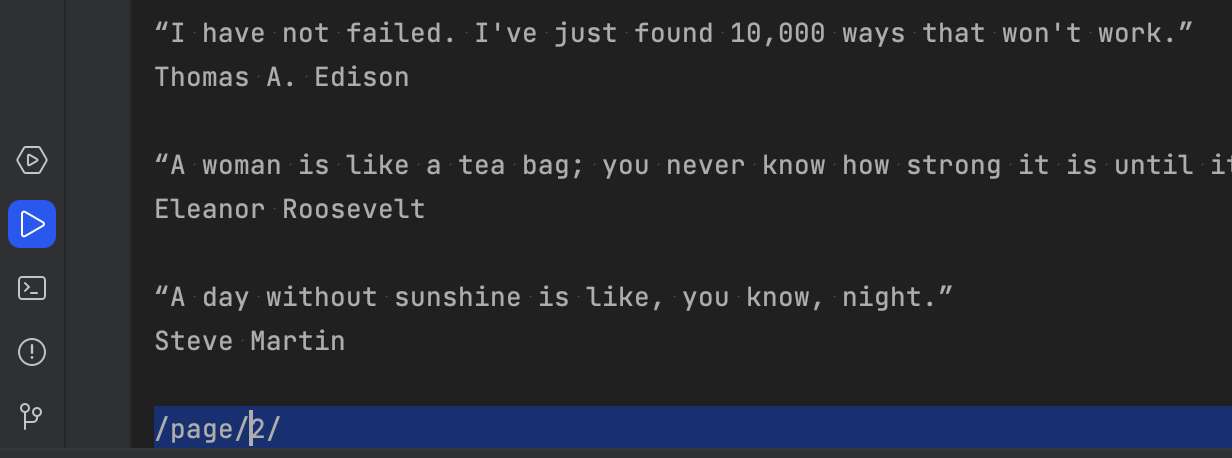
Така проблема періодично виникає. Тому варто використовувати метод urljoin, викликаний через стандартну бібліотеку urllib.parse.

Завдяки цьому основний URL, наявний від початку (або такий, що не треба вичитувати кожен раз заново), з’єднується з локатором на певну сторінку.
Передаємо поєднаний url далі та перевіряємо дані з другої сторінки. Результат: все пройшло добре, оскільки дані оновилися. І тепер ми маємо посилання на 3-у сторінку /page/3/.
Про всяк випадок можна зробити ще одну перевірку. Остання цитата, яку витягнув парсер на 3 сторінці, належить Бобу Марлі.
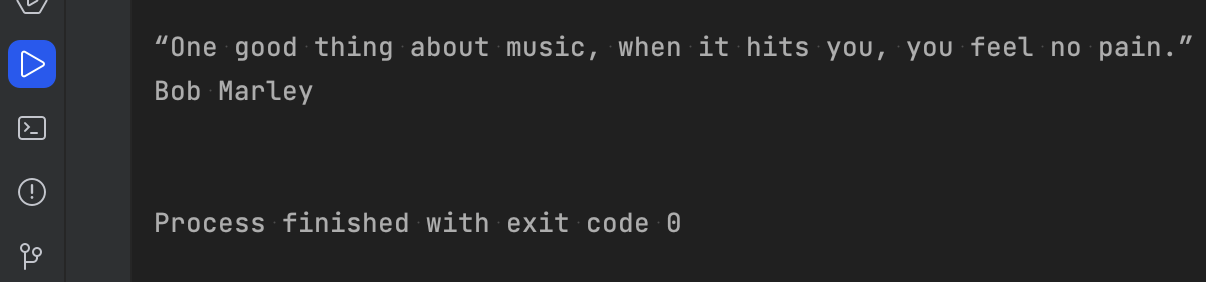
Переходимо на сайт, відкриваємо третю сторінку. Все збігається! Тобто ми змогли правильно пройтися різними сторінками та витягнути потрібний контент.
Бібліотеки BeautifulSoup та lxml – це чудові інструменти, які задовольнять мінімальні потреби скрейпінгу. Але вся додаткова робота, як-от перехід між сторінками чи очищення даних, лежатимуть на наших плечах. Якщо ж вам хочеться автоматизувати цю роботу, варто використовувати саме Scrapy.
Як працювати зі Scrapy
Процес інсталяції Scrapy стандартний. Достатньо виконати команду pip install scrapy:

У моєму випадку всі залежності вже попередньо встановлені. У вас же додавання всіх бібліотек або їх частини може потребувати часу. Після цього запустіть команду scrapy startproject testing. Вона створить мінімально потрібну структуру директорій для проєкту та початкові файли, які знадобляться на різних етапах роботи (конфіги, шаблони тощо).

Далі з’являється директорія testing, в якій є ще одна директорія testing та файл scrapy.cfg. А вже всередині другої testing знаходяться необхідні файли для автоматизації скрейпінгу й окрема директорія spiders, де будуть зберігатися скрейпери.
Я створив це все завчасно, тому у прикладі працював із готовими директоріями. Ви ж можете повторити попередній крок та обрати інше імʼя для проєкту.
Також варто взяти більш реальний та наочний приклад, ніж описаний сайт із цитатами. Чудово, що в цьому домені toscrape.com є ще один сайт – books.toscrape.com. Він емулює такий собі онлайн книжковий магазин. Однак, перед розбором самих парсерів, давайте спочатку подивимося на налаштування наших скрейперів. Усі налаштування збережені у файлі settings.py у директорії вашого проєкту.
Тут зібрані всі доступні параметри Scrapy: кількість одночасних запитів, використані проміжні застосунки, налаштування авто тролінгу тощо. Раджу після цього туторіалу відкрити офіційну документацію та більш детально ознайомитися з налаштуваннями. А наразі зосередимося на одному параметрі з налаштувань, а саме – ROBOTSTXT_OBEY.
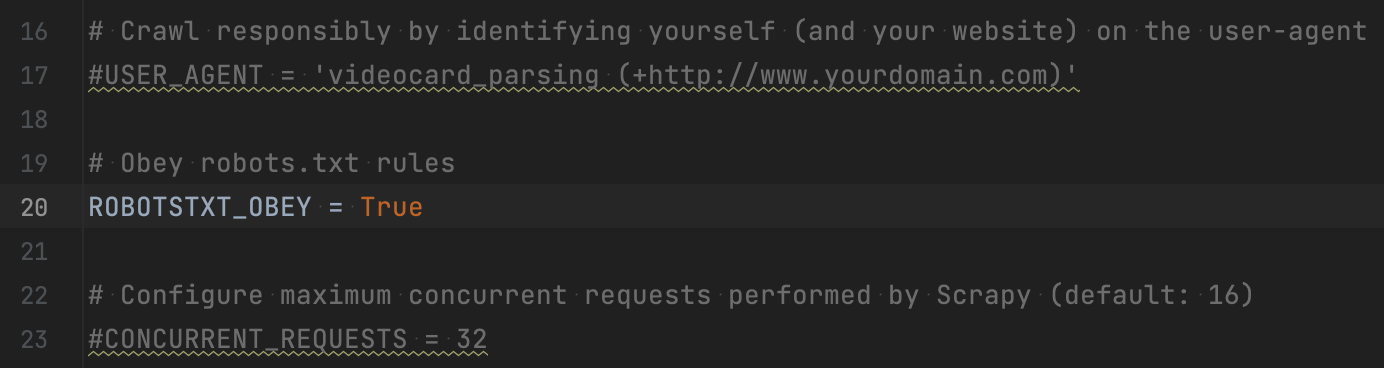
Майже кожен сайт, який вам захочеться розпарсити, має файл robots.txt. У ньому розміщується набір правил, які дозволяють та забороняють певні дії на сайті для скрейперів. Наприклад, це можуть бути обмеження на відвідування певних розділів і сторінок, ліміти на частоту використання скрейпера тощо. Іноді ці заборони можна обійти технічно, але ви можете отримати за це бан від сайту.
Також у цьому файлі містяться вказівки для user-agents різних пошукових роботів. Наприклад, на сайті техніки, який ми аналізуємо, цей файл має такий вигляд:
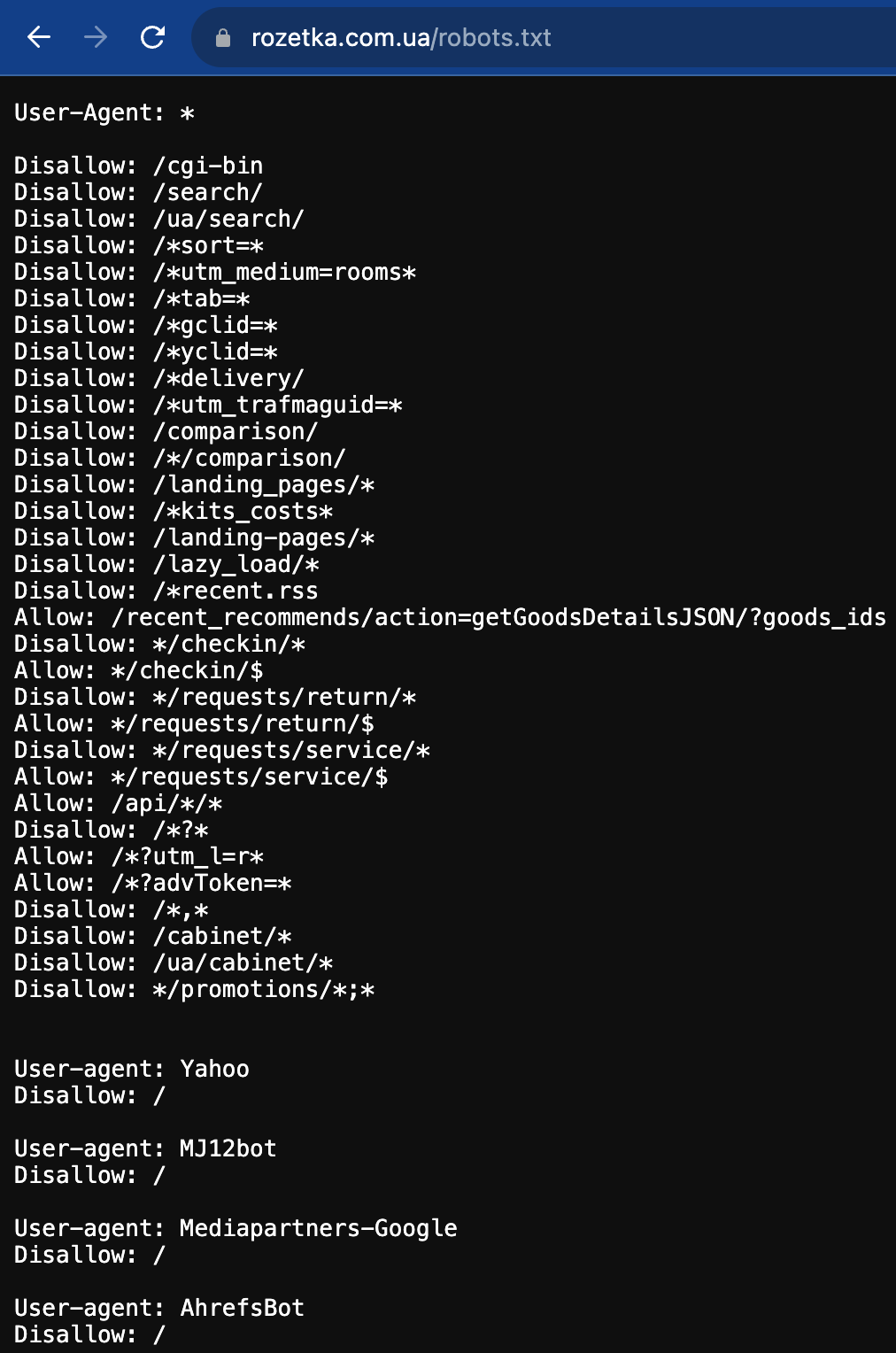
Тож перш ніж починати працювати зі скрейперами, ознайомтеся із дозволами конкретних сайтів.
Повернімося до скрейперів. Нижче зображено простий метод, який витягуватиме дані з потрібного нам сайту:
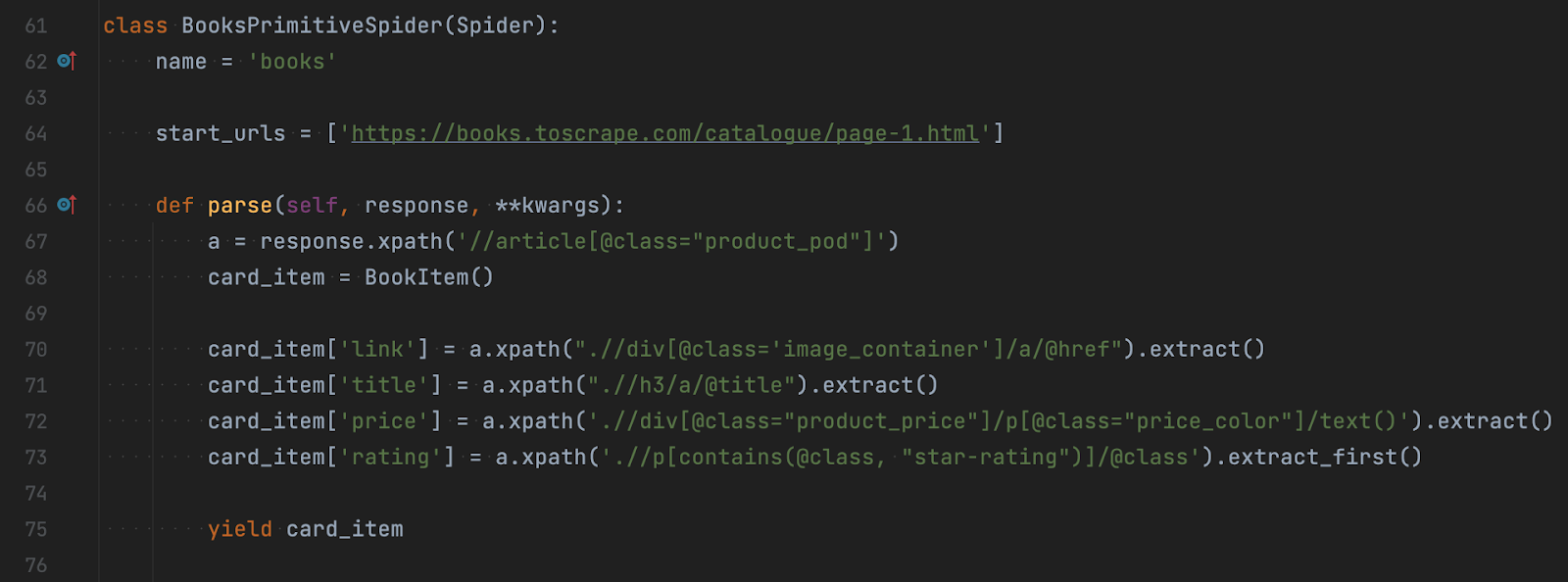
Скрейпер має ім’я, необхідне для виклику. Наступним вказано початкове посилання для парсингу і власне метод, який займається цим процесом. Всередині метода ви бачите, як спочатку ми шукаємо по всій сторінці елементи article із класом product_pod. Після цього всередині елемента шукаємо заголовок, посилання, ціну та рейтинг книги.
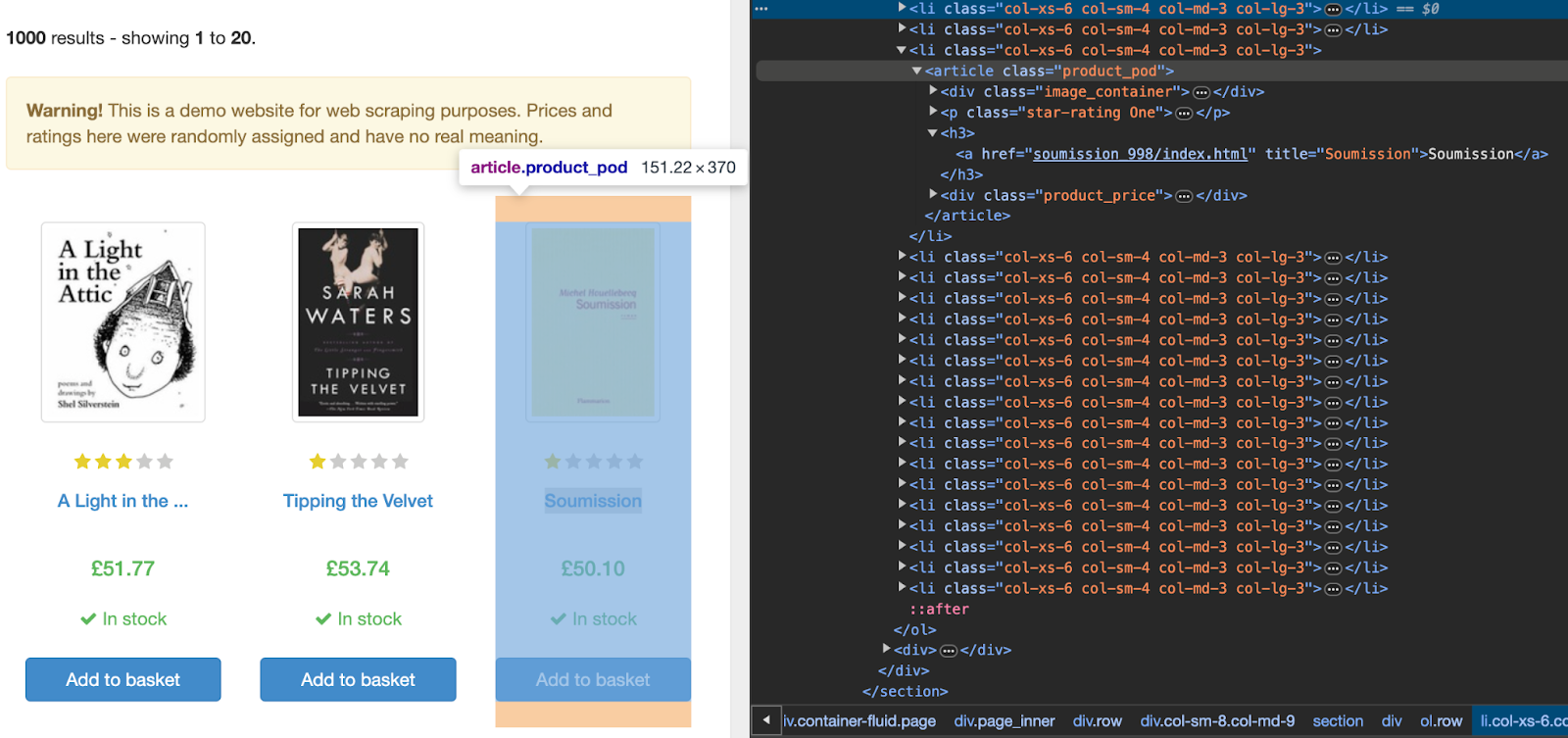
Зверніть увагу на теги сторінки та порівняйте їх із xpath, які використовувалися для пошуку елементів. Особливо придивіться до останніх елементів у рядках.
Залежно від обʼєкта ми можемо звертатися до атрибута text(), який передасть текст всередині тега. А можемо спробувати дещо інше – звернутися до @href для отримання посилання чи до @class (у цьому прикладі оцінка в текстовому варіанті вказана лише у значенні класу).
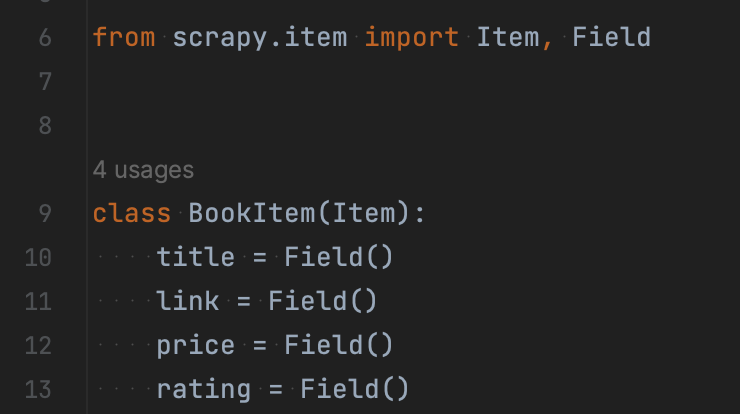
Окрім рядків із безпосередньо парсингом сторінки, ви можете бачити екземпляр класу BookItem. Загалом Items у Scrapy – більш зручний спосіб звернення до елементів, які ми шукаємо. Можете думати про них як про словник, що зберігатиме імʼя поля та його значення.
Для нашого скрейпера книжок я створив простий Item, що складається із чотирьох полів: заголовка, посилання, ціни й рейтингу товару.
Тепер спробуємо запустити наш перший Scraрy-проєкт. Зробити це можна за допомогою команди Scrapy crawl <crawler_name>. Наприклад:

Результат роботи виводиться в термінал і виглядатиме ось так:
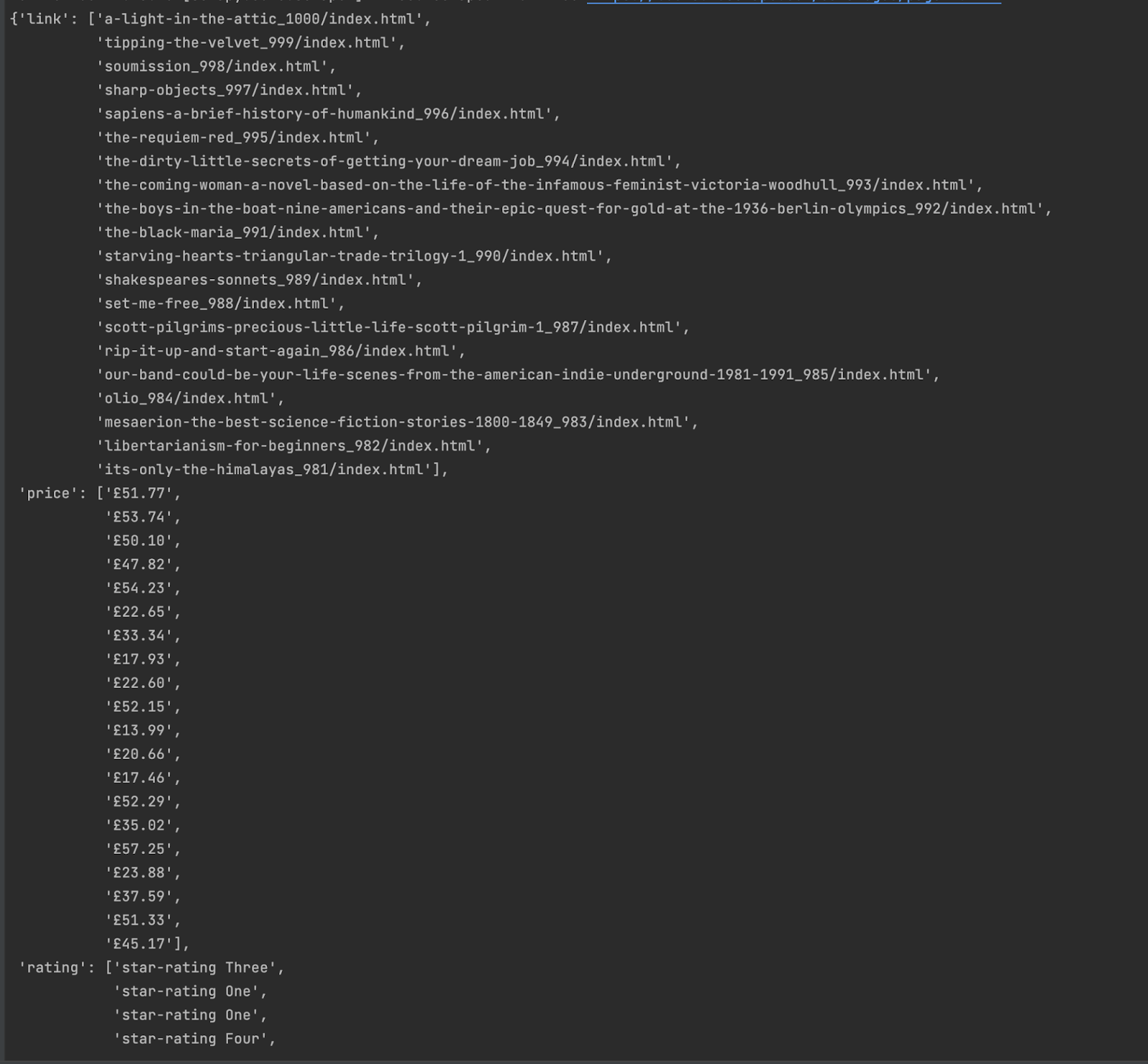
Здається, щось не так... Хотілося б, аби наші Items співпадали з кількістю обʼєктів, які ми розпарсили. Також було б добре, щоб посилання були повноцінними, щоб рейтинг зберігався як нормальне число. Як покращити наші результати?
У Scrapy, окрім власне Item, ще є такий інструмент як ItemLoader. Цей механізм дозволяє автоматизувати деякі задачі з очистки й обробки отриманих даних, перш ніж вони потраплять до Item.
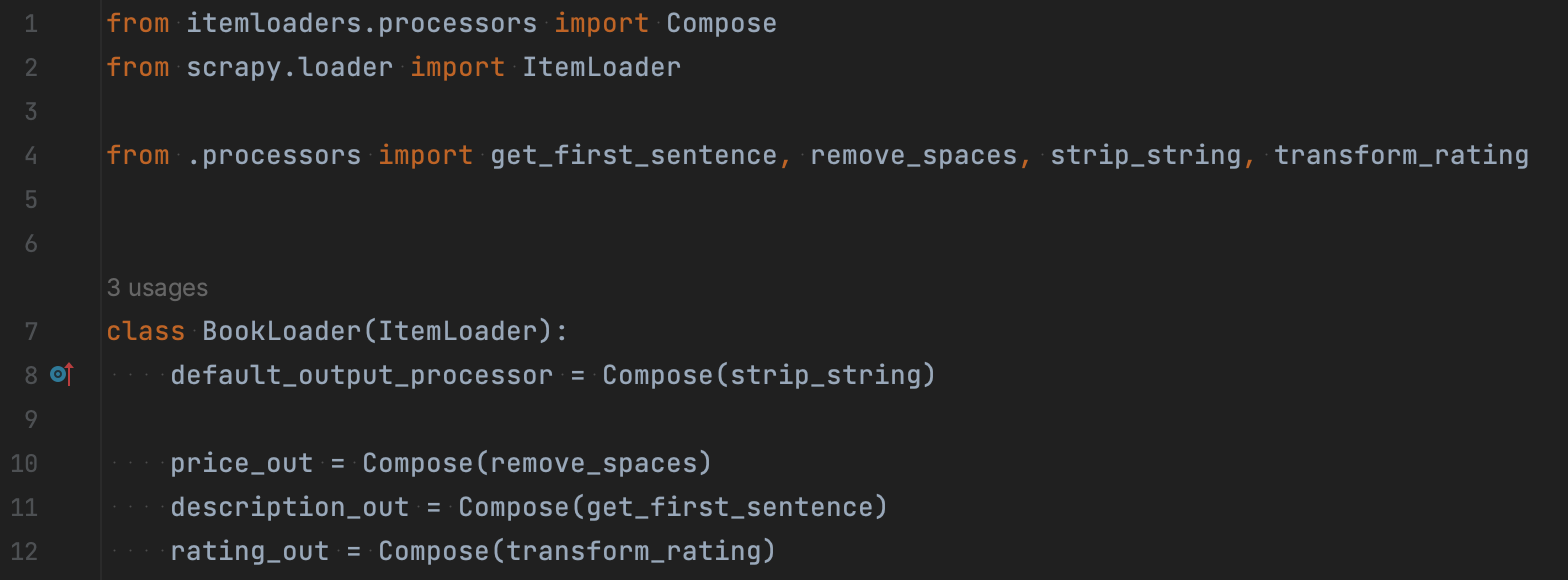
Розглянемо це на прикладі. Нижче ви можете побачити клас BookLoader, що складається з default_output_processor та параметрів, що мають у своєму імені назву, аналогічну певному полю з Item. Як вони працюють?
ItemLoader містить дві частини – Input та Output processors. Якщо бути більш точним, то ItemLoader містить один Input та один Output processor для кожного поля в Item. Input processor обробляє витягнуті дані відразу після їх отримання, а результат збирається та зберігається в ItemLoader.
Після збору всіх даних викликається метод ItemLoader.load_item() для заповнення та отримання заповненого об’єкта елемента. Саме тоді викликається Output processor із попередньо зібраними даними (й обробленими за допомогою Input processor). Результат роботи Output processor є кінцевим значенням, яке призначається Item.
Якщо в нас немає потреби в окремому обробнику для якогось поля, можна вказати default_input_processor та default_output_processor.
Із полями розібрались, а що ж далі? Тепер дізнаємося, що ж за Compose використано в нашому ItemLoader. Compose – це один із стандартних processors, які можна використати для полів в ItemLoader.
Серед основних варіантів згадується TakeFirst, Compose, MapCompose, Identity, SelectJmes, Join. Щоб розібрати їх, уявімо такий приклад: у нас є список вхідних значень у вигляді списку [‘name’, ‘last_name’, ‘price’].
TakeFirst – бере перший елемент зі списку результатів парсингу. Якщо використаємо його, то з нашого списку отримаємо лише перше значення – ‘name’.
Compose – процесор, який складається з композиції заданих функцій. А значить кожне вхідне значення цього процесора передається першій функції, а результат цієї функції передається наступній і так далі, поки остання функція не поверне вихідне значення цього процесора.
У Compose ми можемо передати функції з перетвореннями. Припустимо, ми робимо такий ланцюжок перетворень: Compose(lambda v: v[0], str.upper). У результаті отримаємо одне слово зі списку, написане великими літерами, – ‘NAME.
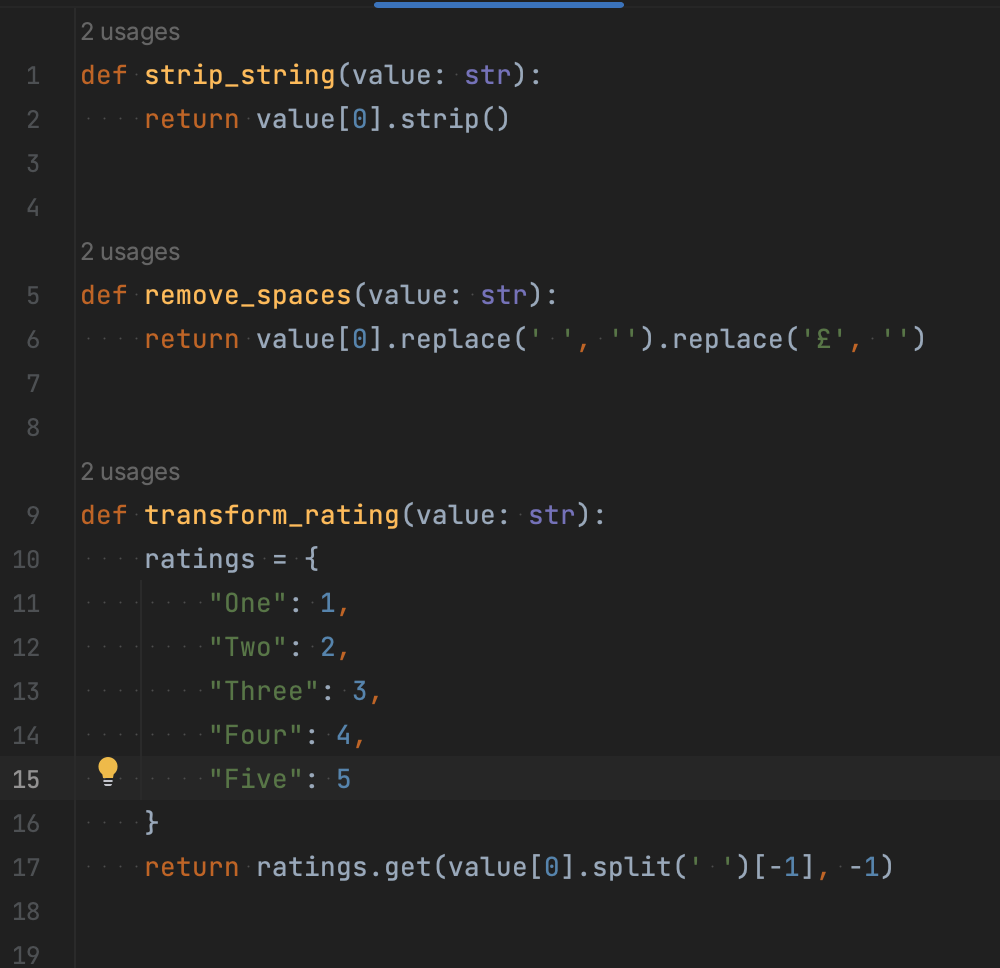
MapCompose працює схожим чином, але застосовує ланцюжок перетворень окремо для кожного елемента зі списку. Тому якщо до нього застосувати ті ж перетворення, що й до Compose, результат буде іншим. MapCompose(lambda v: v[0], str.upper) поверне нам новий список, що буде складатися із перших літер, до яких ми потім застосували метод upper, – ['N', 'L', 'P'].
Identity – найпростіший процесор. Він нічого не робить і повертає дані в такому ж вигляді, що й отримав раніше. SelectJmes використовує JMESPath для вибору даних із результатів парсингу. Нам він знадобиться, якщо ми передаємо JSON-структуру в ItemLoader.
Join – об’єднує список елементів в один рядок, використовуючи заданий роздільник. Тому в нашому випадку він поверне один рядок ‘name last_name price’ або аналогічний, але з потрібним нам роздільником.
Повернемося тепер до нашого прикладу. Ми використовуємо прості Output Processors із Compose. Але раджу вам за можливості спробувати альтернативи. У самій Compose ми передали прості методи для чистки даних:
Настав час оновити скрейпер. Новий код зображено нижче.
Пройдімося по відмінностях:
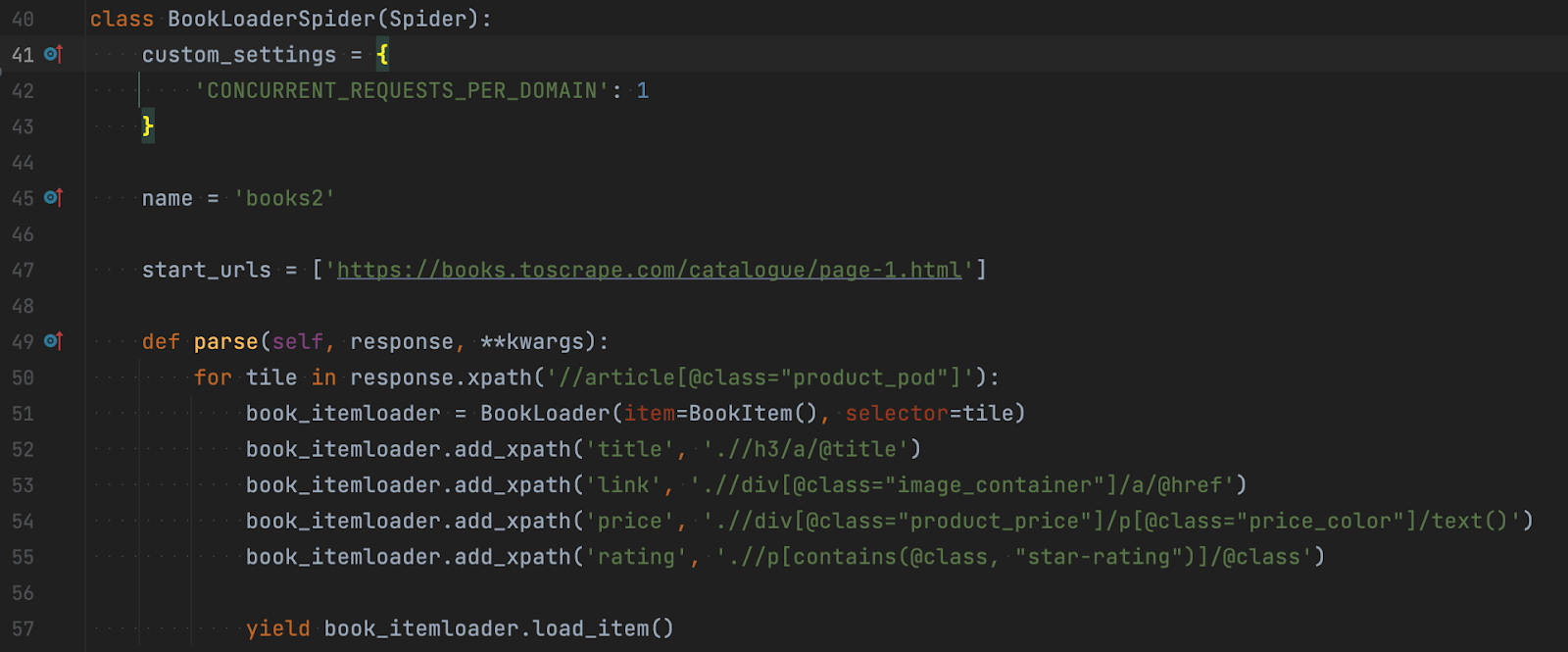
- Ми додали custom_settings. Вказуємо максимальну кількість одночасних запитів на домен, але туди ж можна виписати будь-які інші налаштування. Врахуйте, що такі налаштування працюватимуть лише для потрібного нам скрейпера.
- Додали цикл, який проходиться по всім елементам article, витягує дані та проводить трансформації за допомогою BookLoader. У Loader достатньо передати Item, який буде використовуватися для зберігання даних, і selector, який знадобиться для отримання даних.
Результатом запуску цього скрейпера буде вивід терміналу, схожий на наступний:
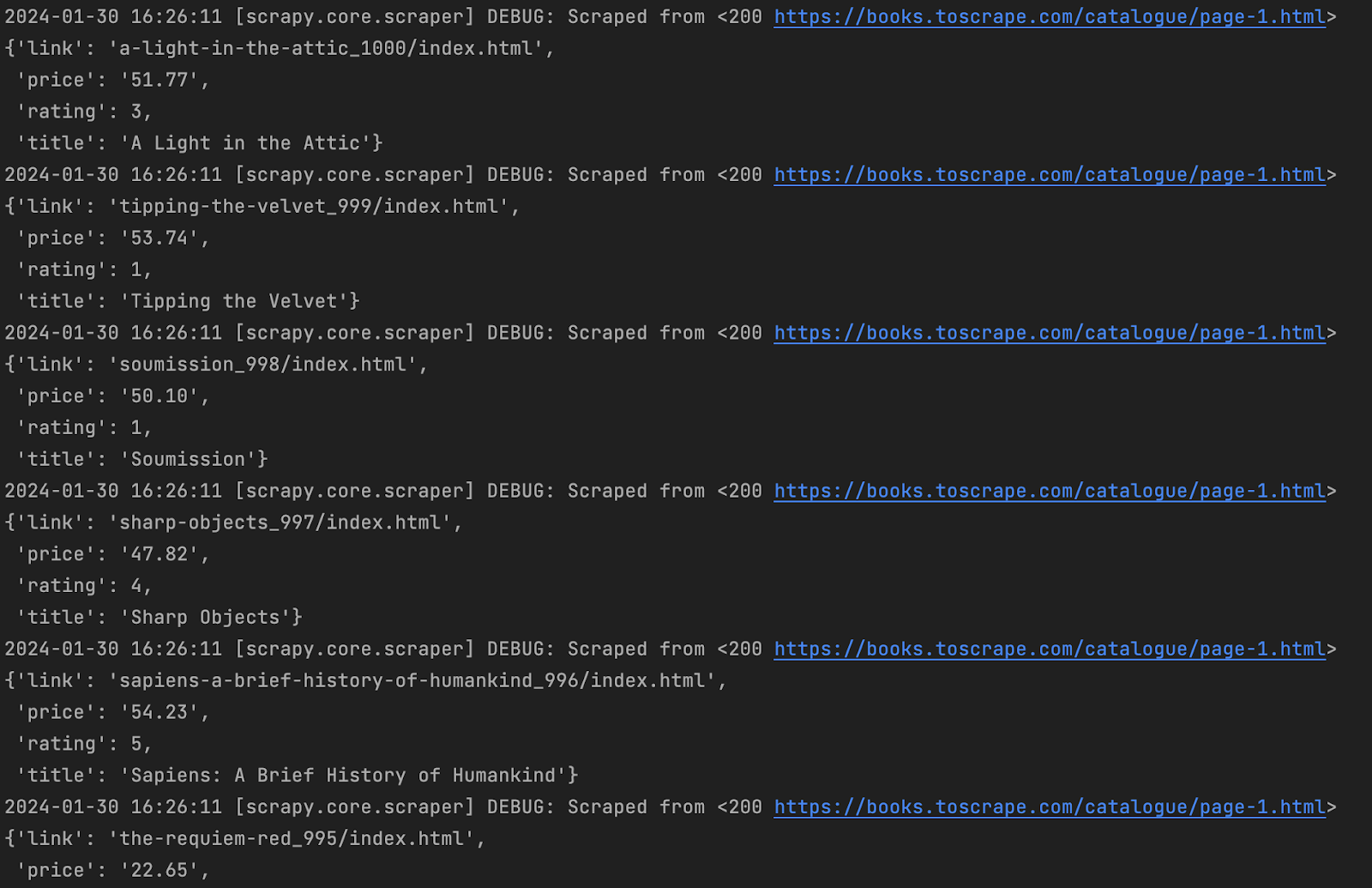
Як бачимо, картинка вже більш корисна. Маємо очищені дані, розділені на окремі сутності. Але і цей результат можна покращити. По-перше, записати дані в інший файл, щоб кожного разу не повертатись до терміналу. По-друге, ми досі працюємо лише з першою сторінкою.
Хотілося б розширити масштаби. Було б зручніше заходити всередину сторінок, щоб, наприклад, витягувати описи книжок. Давайте спробуємо це зробити.
Для початку з’ясуємо, як реалізувати перехід між сторінками та вхід до сторінок кожного обʼєкта. Для цього в Scrapy є механізм під назвою Rule. В ньому ми можемо прописати правила для переходу між сторінками та правила для сторінок, які мають бути прочитані.
З переходом між сторінками ситуація проста. Дивимося на те, як на сайті виглядає перехід між сторінками, і шукаємо наступну. Для поточного сайту перехід такий:
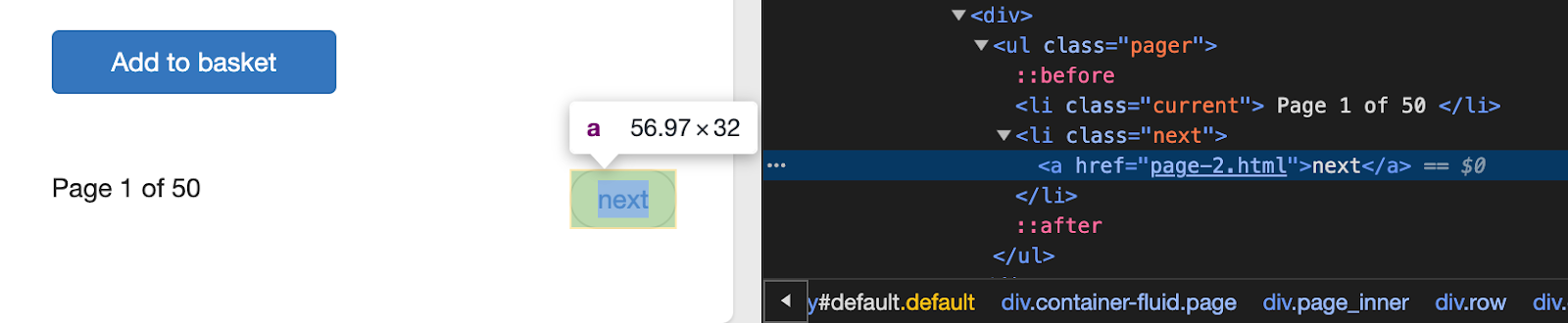
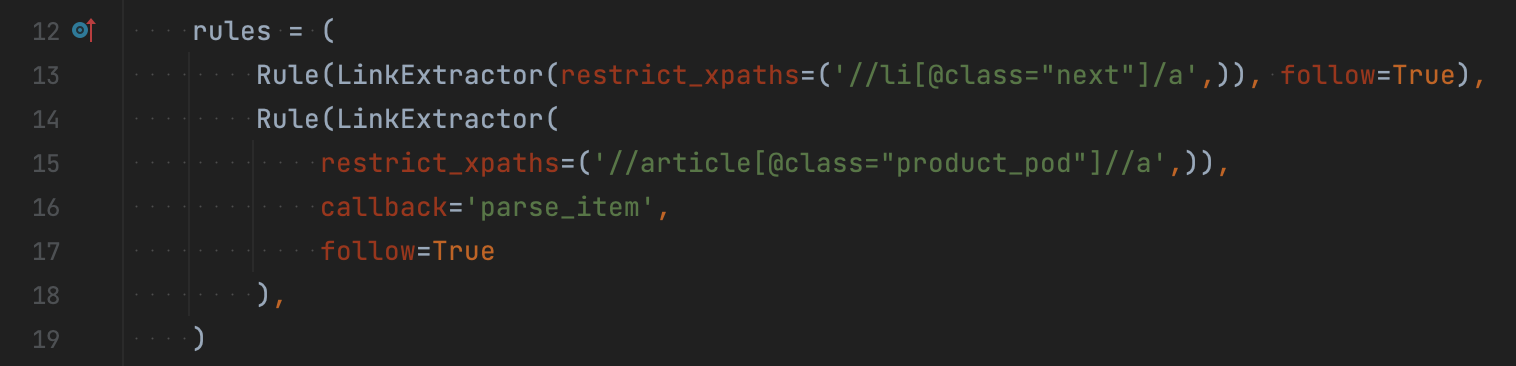
Щодо посилань на сторінки з детальною інформацією про книгу, то вони в нас вже є. Тепер достатньо вказати, що ми будемо робити з цими детальними описами сторінок. На скріншоті нижче можете побачити приклад використання правил.
Перше правило – для переходу між сторінками (зверніть увагу на параметр follow=true, необхідний власне для переходу). Друге правило – для роботи з посиланням на сторінку кожної книги.
Крім того, що заходимо на цю сторінку, ми ще й будемо викликати метод parse_item, який отримуватиме дані:
Що ж стосується другої частини – збереження в файл, то й тут у Scrapy є готовий інструмент – це Pipelines. Після того, як Item був зібраний, він надсилається до Item Pipeline, який обробляє його за допомогою кількох компонентів, які виконуються послідовно.
Кожен такий Pipeline – це клас Python, що реалізує прості методи. Вони отримують елемент і виконують над ним певну дію, а також вирішують, чи повинен елемент продовжувати проходити по конвеєру чи має бути видалений і більше не оброблятися.
Давайте створимо простий Pipeline, який збиратиме книги у файл, але якщо ці книги не дорожчі за 30 умовних одиниць:
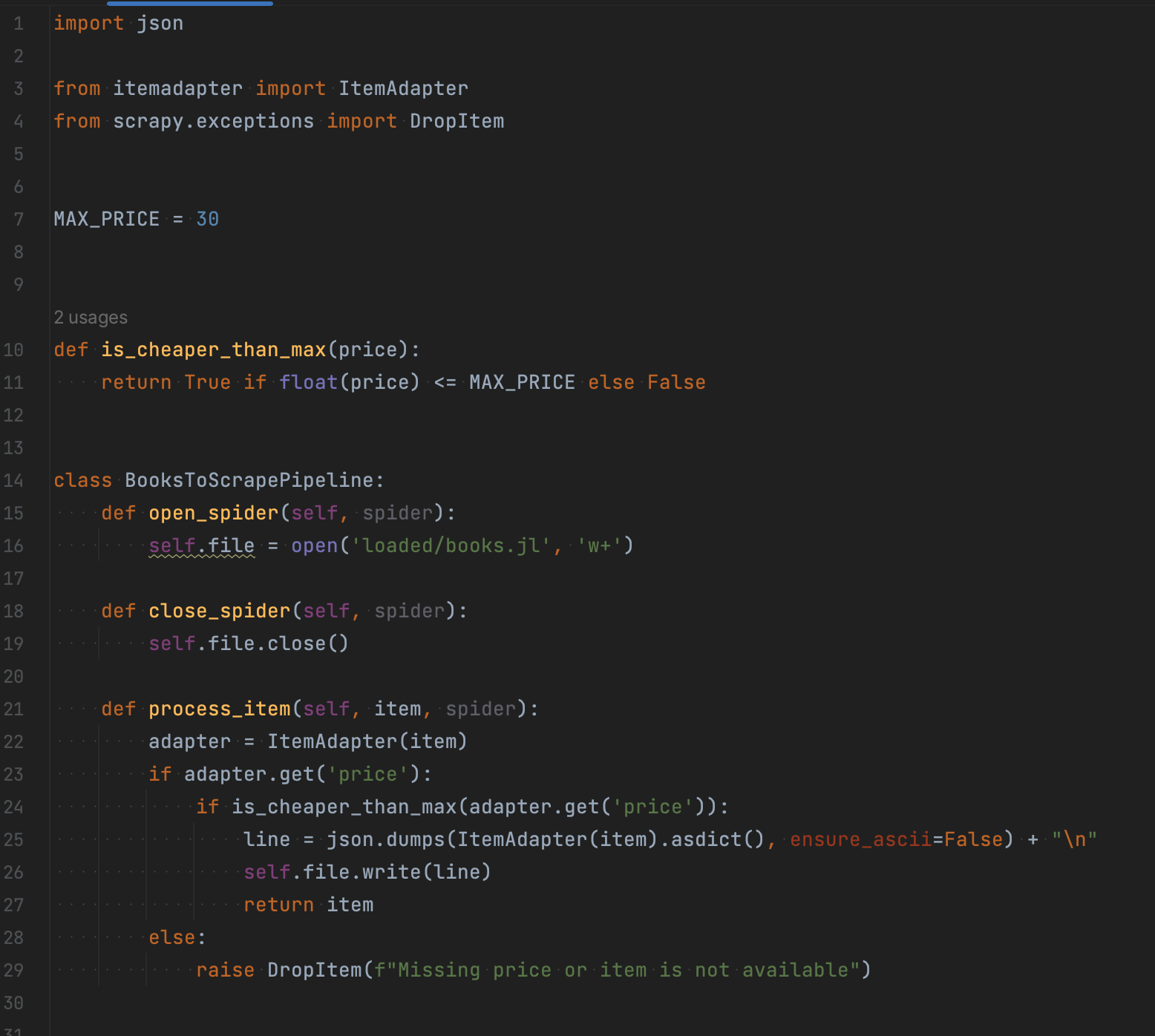
На скріншоті зображено три основні методи ItemPipeline:
- open_spider – викликається, коли відкривається скрейпер;
- close_spider – те ж саме при закритті скрейпера;
- process_item – власне обробник.
Щойно запустивши скрейпер, ми створюємо або перезаписуємо файл books.jl. Потім за допомогою process_item перевіряємо ціну товару, використовуючи функцію is_cheaper_than_max, або пишемо товар до файлу чи викидаємо, якщо він підходить під нашу умову. Насамкінець закінчуємо запис до файлу.
Погляньмо тепер на код нашого скрейпера цілком:
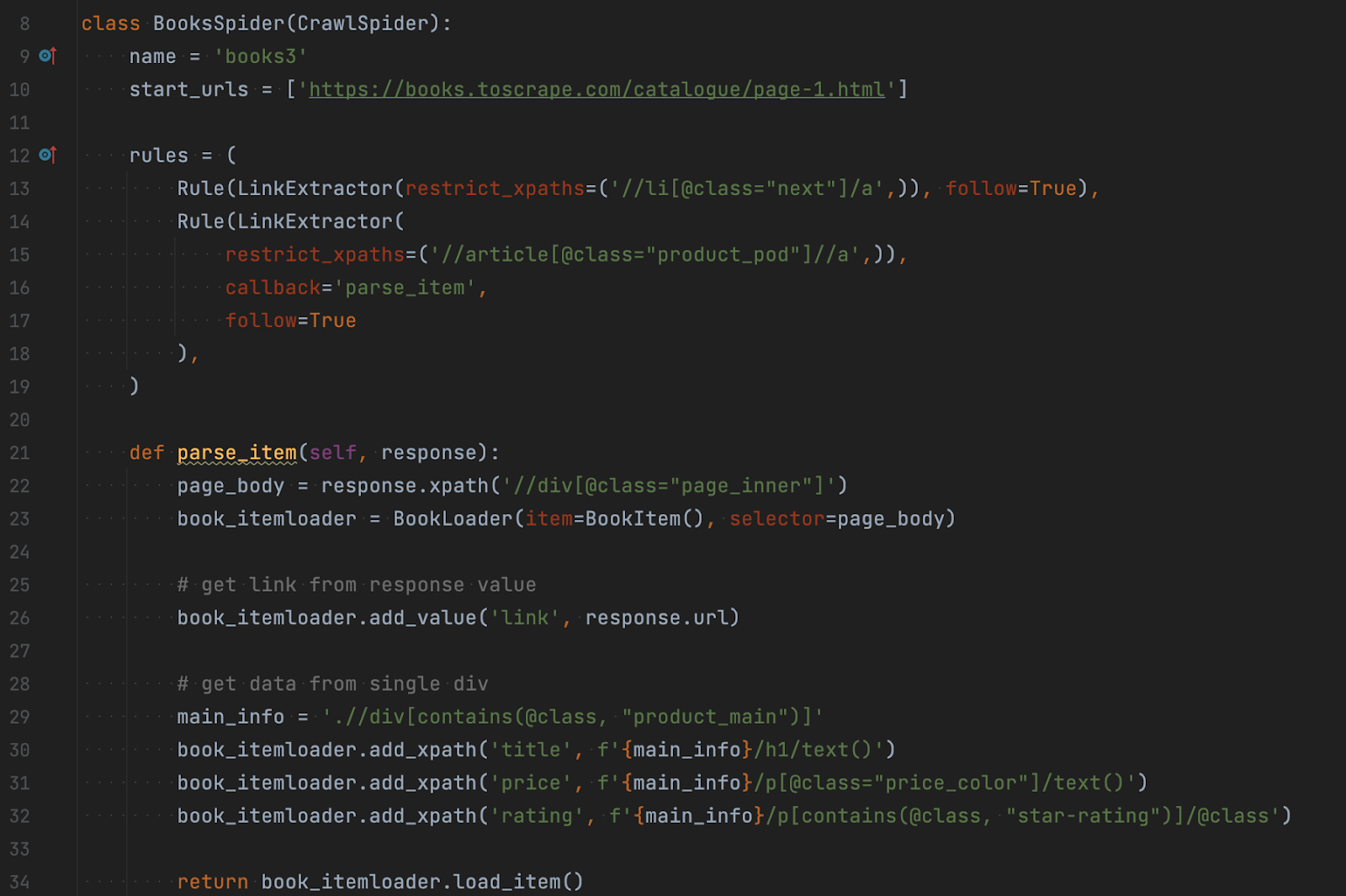
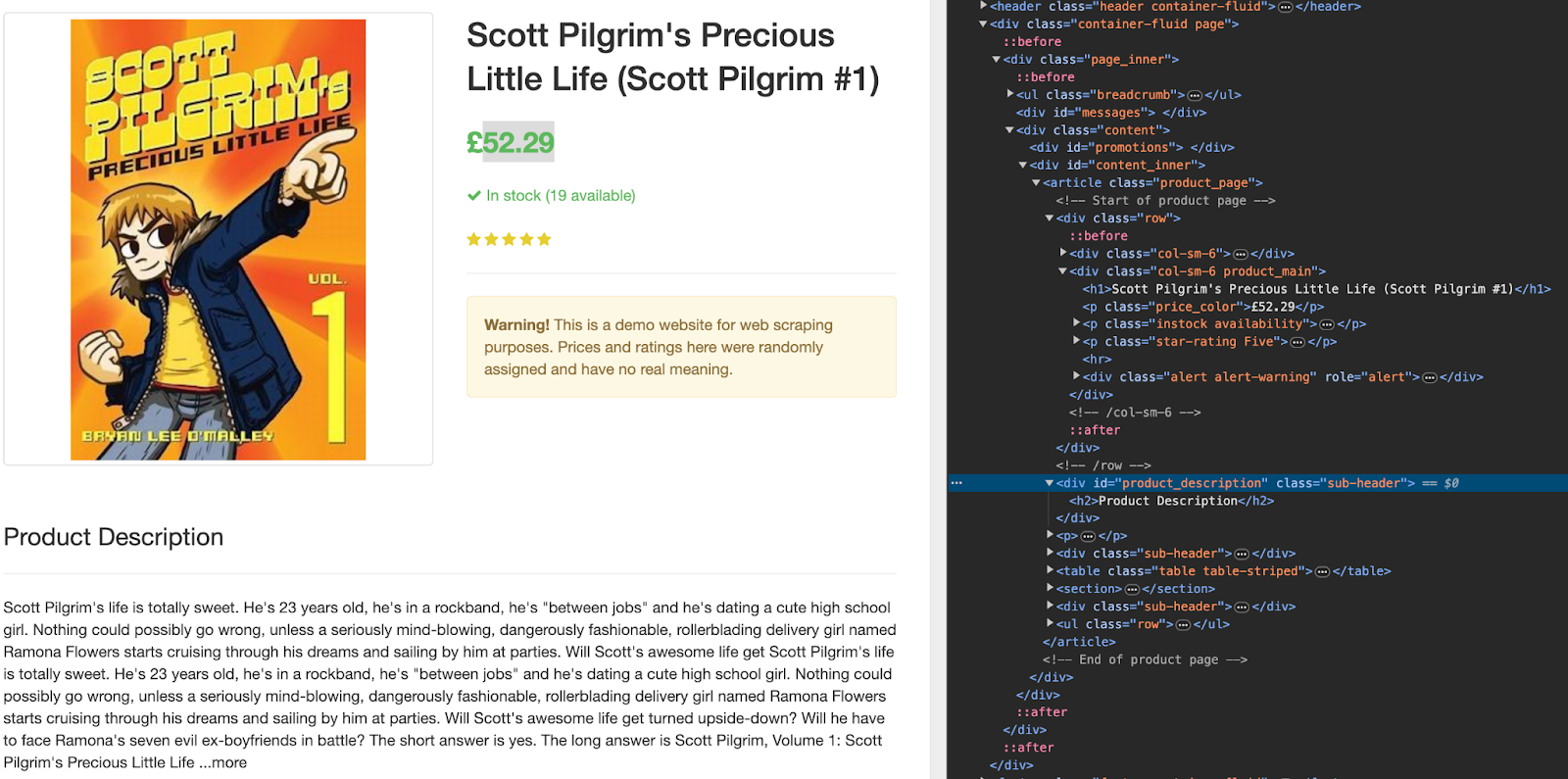
Що змінилося? Ми додали правила переходу між сторінками. Тепер у parse_item ми працюємо зі сторінкою конкретної книжки замість головної. Тож оновилися поточні конструкції xpath. На саму ж сторінку ви можете подивитися на скріншоті нижче:
Однак, де нам викликати наш пайплайн, щоб зберігати дані у файл? Для цього розкоментуємо (або додамо самостійно) словник ITEM_PIPELINES:

У ньому пропишемо шлях до класу і пріоритет виклику пайплайну (в цьому випадку – число 300). Якщо б у нас були додаткові пайплайни, то вони викликалися б у порядку від найменшого значення до найбільшого.
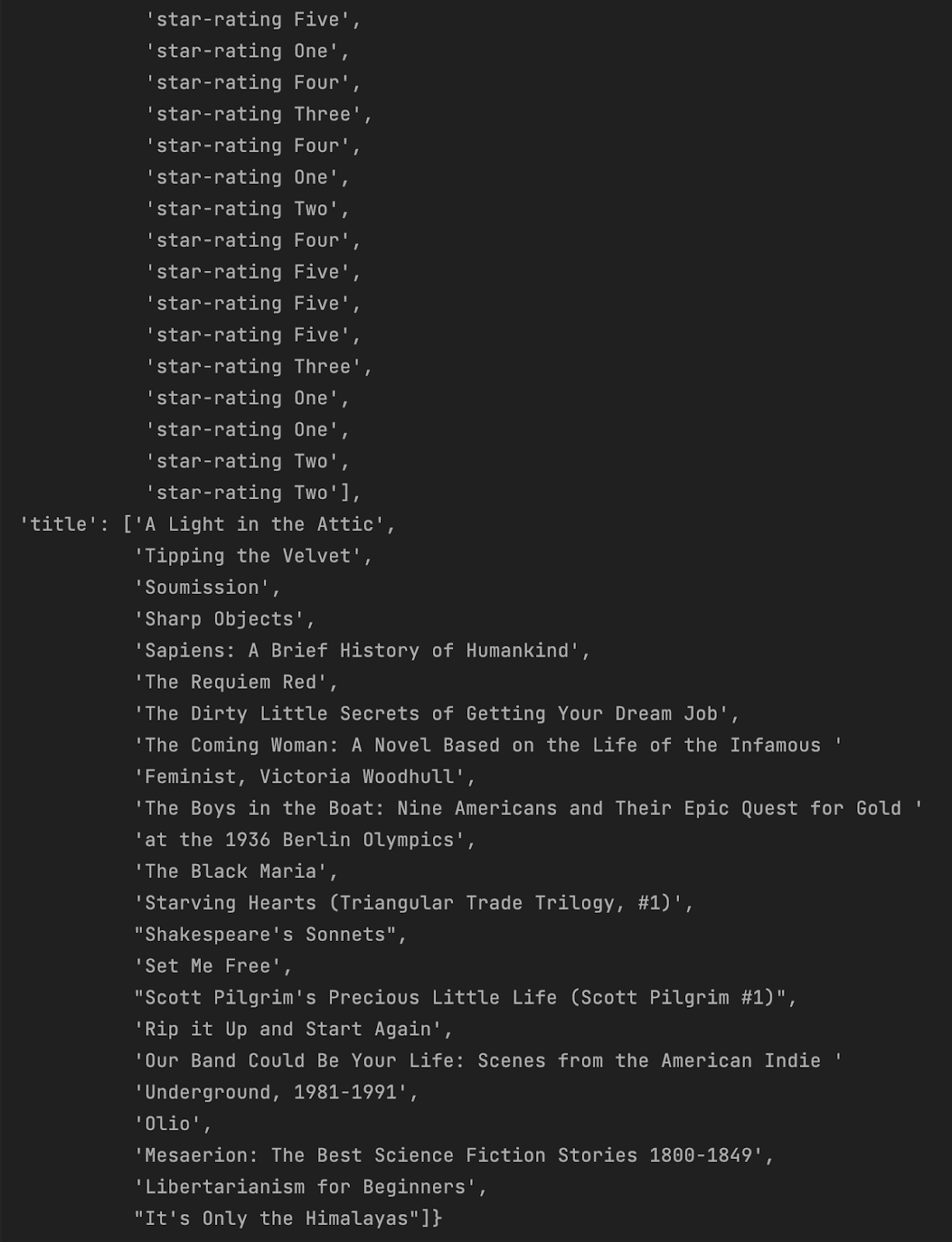
Дивимося на оновлені результати. З 1000 книг, що є в каталозі, збережено 403, вартість яких менша за 30 одиниць. Також ми успішно витягнули потрібні значення та зберегли описи із цифровими оцінками, скороченими описами та посиланнями на книги:
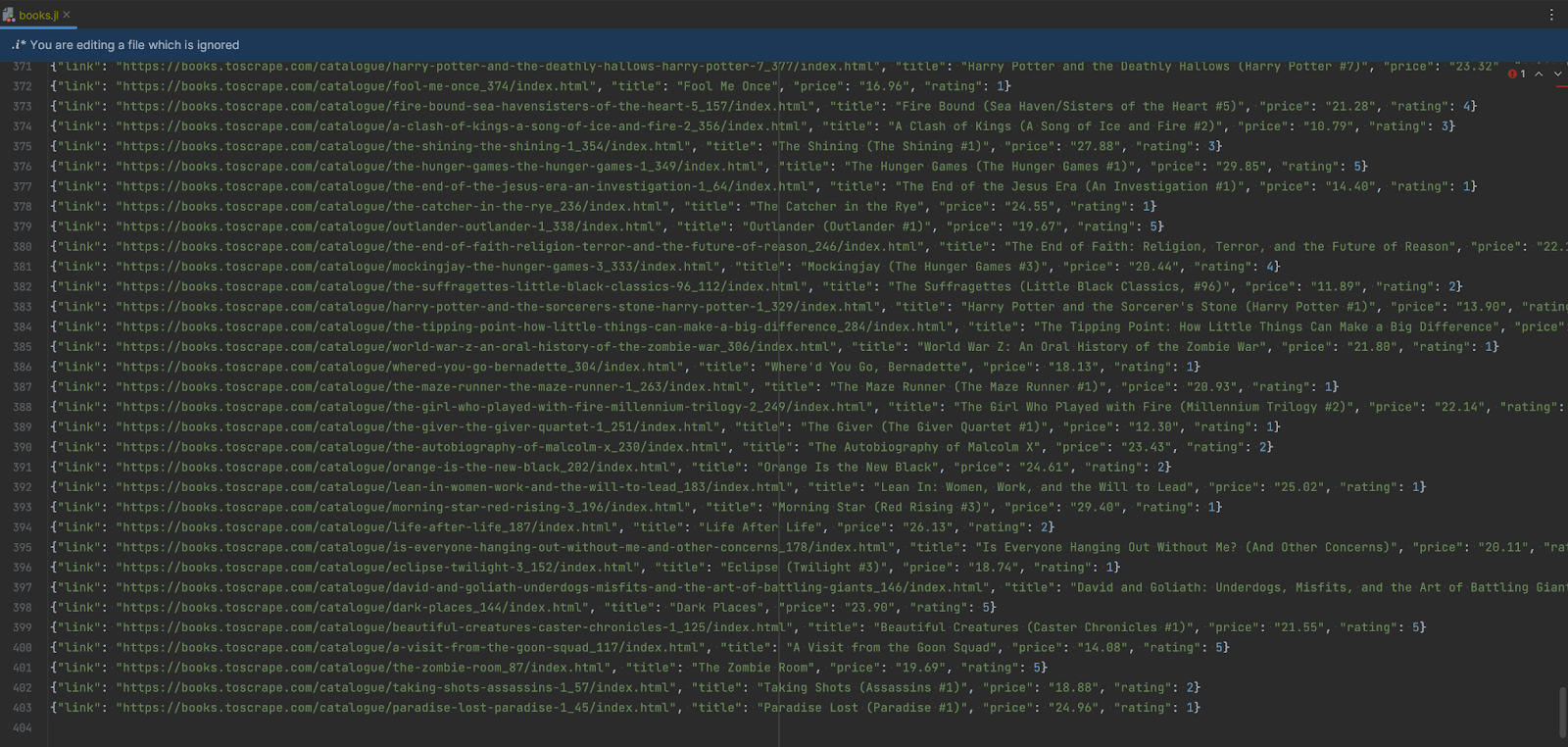
Тож вітаю, ви успішно отримали дані! У потрібній формі та з використанням необхідних фільтрів. Можу тепер лише порадити продовжувати опановувати Scrapy, вивчати нові способи роботи з ним і завжди памʼятати про етику у роботі з чужими ресурсами.
Наведені у статті приклади – лише верхівка айсберга. Я намагався показати якомога більше прикладів того, як ви можете працювати з різними інструментами скрейпінгу.
Якщо ж прагнете повноцінно опанувати скрейпінг, то у цій темі на вас чекає ще чимало відкриттів. Звернуть увагу на автоматизацію роботи пайплайнів. Подивіться на сервіси на кшталт Zyte, які дозволяють розмістити ваші скрейпери в мережі, або подумайте над додаванням бота в Telegram чи Viber.
Підписуйтеся на ProIT у Telegram, щоб не пропустити жодної публікації!